机器学习:解读基因密码「食谱」
- 2015-10-21 08:48:00
- 刘大牛 转自文章
- 760
 每份食谱都有烹饪指南和配料介绍。人类基因组也是如此。指南出了问题,就会有患病的风险。[/caption]
到目前为止,所有的基因研究都专注于基因组的那百分之一,也就是为蛋白质指定遗传密码的部分。但是,一项发表在《科学》杂志上的新研究却首次绘制出了负责蛋白质制造过程的那部分基因组图谱。多伦多大学的计算机生物学家Brendan Frey领导了这项新研究,他说,「有书看是一回事,但最大的问题是怎么读这本书。」
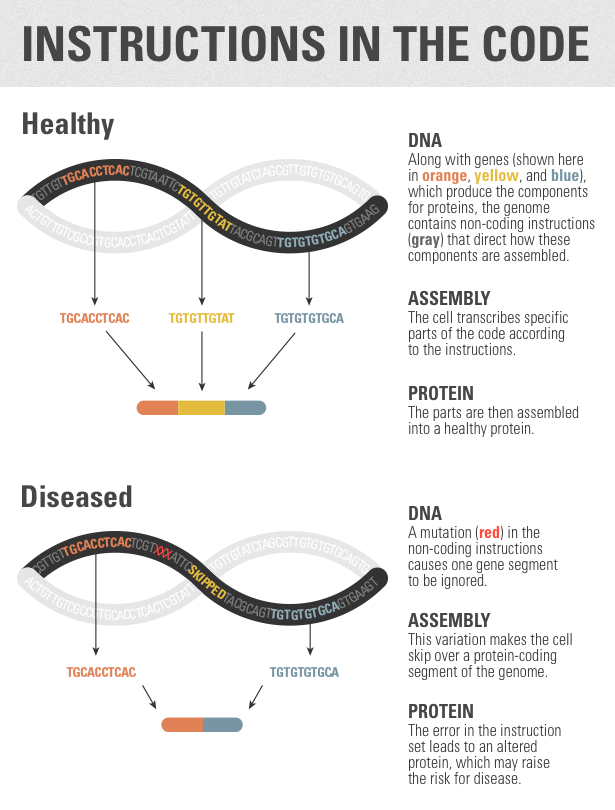
Frey将基因组比喻成烹饪食谱。所有的食谱都既包括配料清单,比如面粉、鸡蛋和奶油,也有做法指导。在细胞里,配料就是为蛋白质指定遗传密码的那部分基因组;围绕它们的是基因组指令,告诉它们如何使用这些配料。
面粉、鸡蛋和奶油能做出几百种不同的烘焙食物,同样,基因成份也有很多种组合方式。这一过程就是可变剪接(alternative splicing),也是细胞从单一基因代码创造出如此多的细胞种类的过程。Frey和他的同事使用了一种成熟的机器学习模型(form)来识别这套指令集中的突变,预测这种突变可能造成的影响。
[caption id="attachment_5294" align="aligncenter" width="615"]
每份食谱都有烹饪指南和配料介绍。人类基因组也是如此。指南出了问题,就会有患病的风险。[/caption]
到目前为止,所有的基因研究都专注于基因组的那百分之一,也就是为蛋白质指定遗传密码的部分。但是,一项发表在《科学》杂志上的新研究却首次绘制出了负责蛋白质制造过程的那部分基因组图谱。多伦多大学的计算机生物学家Brendan Frey领导了这项新研究,他说,「有书看是一回事,但最大的问题是怎么读这本书。」
Frey将基因组比喻成烹饪食谱。所有的食谱都既包括配料清单,比如面粉、鸡蛋和奶油,也有做法指导。在细胞里,配料就是为蛋白质指定遗传密码的那部分基因组;围绕它们的是基因组指令,告诉它们如何使用这些配料。
面粉、鸡蛋和奶油能做出几百种不同的烘焙食物,同样,基因成份也有很多种组合方式。这一过程就是可变剪接(alternative splicing),也是细胞从单一基因代码创造出如此多的细胞种类的过程。Frey和他的同事使用了一种成熟的机器学习模型(form)来识别这套指令集中的突变,预测这种突变可能造成的影响。
[caption id="attachment_5294" align="aligncenter" width="615"]
 Olena Shmahalo/Quanta Magazine[/caption]
研究人员已经识别出可能引发自闭症的风险基因,目前正在研发一种系统,用以预测与癌症有关的基因突变是否有害。MIT计算机生物学家Chris Burge(没有参加这项研究)认为,「论文为基因科学家们提供了识别利害相关变异(variants of interest)的工具,希望能对人类基因领域的研究有重大影响。」
但是,这项研究的真正重要性可能在于这些新工具,它们能探测到庞大的DNA片段,到目前为止,我们还很难解释这些片段。许多基因研究只对产生蛋白质的小部分基因组进行了排序。休斯顿贝勒医学院的生物学家Tom Cooper 说,「这也论证了对整个基因组进行测序的重要性。」
Olena Shmahalo/Quanta Magazine[/caption]
研究人员已经识别出可能引发自闭症的风险基因,目前正在研发一种系统,用以预测与癌症有关的基因突变是否有害。MIT计算机生物学家Chris Burge(没有参加这项研究)认为,「论文为基因科学家们提供了识别利害相关变异(variants of interest)的工具,希望能对人类基因领域的研究有重大影响。」
但是,这项研究的真正重要性可能在于这些新工具,它们能探测到庞大的DNA片段,到目前为止,我们还很难解释这些片段。许多基因研究只对产生蛋白质的小部分基因组进行了排序。休斯顿贝勒医学院的生物学家Tom Cooper 说,「这也论证了对整个基因组进行测序的重要性。」
阅读食谱
剪接代码仅是非编码基因组的一部分,虽不生产蛋白质却非常重要。大约90%的基因会进行可变剪接,科学家估计所有与疾病相关突变中,剪接代码变异占了10-50%。Frey说,「管理代码发生突变,健康就会有大问题。」 耶鲁大学的生物信息学家Mark Gerstein(未参与这项研究)说,「过去,人们之所以专注蛋白质编码部分的突变,某种程度上是因为他们能更好地处理这些突变所为。随着对蛋白质编码区域之外DNA序列理解的加深,我们也会更好地认识到它们对疾病治疗的重要性。」 科学家们已经开始理解细胞如何选择某种特定蛋白质组合,但是支配这一过程的许多代码仍是个谜。2010年,Frey团队发表过一篇论文,他们识别出了老鼠基因组内一个支配剪接的粗糙代码(a rough code)。过去四年,基因数据,特别是人类数据的质量显著提高,机器学习技术日益成熟,为Frey及其合作者的这项研究提供了可能:人类基因组中,许多点上的特定突变如何影响到可变剪接。MIT计算机生物学家Manolis Kellis(未参与这项研究)说,「最终,全基因组数据库让这种预测成为可能。」Frey 讨论他的团队如何用深度学习来了解基因组以及为什么他相信「我们发现的这种技术能够革命医疗。」
Frey的团队利用深度学习的方法。正如任何一种机器学习的算法,建立模型去发现两组数据之间的关系。在这个案例中,是两组取自不同身体组织的基因样本,所携带的蛋白分子数量不同(就像两个蛋糕食谱有着不同的面粉和糖的配比,大脑细胞和肝细胞产生的每种蛋白质的数量也不尽相同)。本质上,是用算法训练了一个计算机模型,让它可以读取DNA中埋藏的基因指令。
其实,科学家们早已经知道如何读取基因剪接密码,但是新的模型有一个非常独特之处——可以让科学家预测一大串基因组织之间的互相影响。Burge说:「这个团队将我们已知的剪接密码数据放到一个计算机模型中,从中我们能够衡量所有变量。」
例如,研究人员可以利用模型去预测当管理代码中发生错误时,蛋白质会发生什么事情。蛋白质剪接过程中的突变已经证实可导致包括脊髓性肌肉萎缩症(造成婴儿夭折的一个主要原因)以及直肠癌。在最新研究中,研究员运用训练过的模型去分析一些患者的基因数据。他们发现了一些已知的突变与疟疾的联系,证明了模型的有效性。他们还挑选出了一些具有有自闭症倾向的突变基因样本。
Frey说这个模型的优点之一是该数据库并不是用疾病数据来训练的,因此它能够分析任何疾病或者感兴趣的特征。研究人员计划将该系统开放,这样科学家们就可以将该模型应用在更多种类的疾病分析上。
更广的语境
Frey说这个模型还表明,「语境对基因组非常重要,就像英语中的『Cat』可以表示一种宠物,也可以指一种建筑设备(译者注,指卡特彼勒(CAT)公司的建筑机械)。」同样的,细胞如何诠释一系列剪接指令是依赖于附近其他的指令。一串带有「制造大量组件X」指令的DNA,当它附近有第二组指令时,可能意味着「不要制造组件X」。Frey说,「一个序列是否产生影响,取决于其他序列是否发挥影响。不理解这一点,就很难去预测一个模型将如何影响剪接。」
另外,这个模型能帮科学家反思已知的突变,Burge说。研究者已经知道,蛋白质编码区域的一些剪接指令已经被发现。在这些情形下,相同的基因序列能够对成分以及如何处理它的指令进行同时编码。(想想whipped cream(生奶油,或者掼奶油)——它是一种成分,但在某种情形下也是一种指令。)在这个蛋白质编码区域的突变,如果它对于改变相应蛋白质贡献很少,它就会被视为不重要而被舍弃。但是当解读剪接编码时,此突变可能会通过干扰剪接指令,而展现出深远的影响。Frey的团队在基因组中发现了许多相关错误的例子。
Frey希望这个模型最终能对个性化医疗发挥用处。例如,医生还不能决定某些健康人携带的新突变是否有癌变等恶化的倾向。假如进行更多的验证, Frey的模型可能将有助于回答这个问题。 Frey说,「我们能分析任何突变,甚至是那些还没有被识别的突变」。这使得研究员可以去预测新突变是危险的还是无害的——从本质上说,这就是执行一个筛查测试。他说,「我希望它对医疗产生重大影响,我想将它用于实践。」
本文选自quantamagazine,作者Emily Singer,人工智能站翻译出品。参与人员:微胖,妞妞姐姐,salmoner,汪汪。
| 联系人: | 透明七彩巨人 |
|---|---|
| Email: | weok168@gmail.com |
