<Effective Approaches to Attention-based Neural Machine Translation >
1. This paper examines two simple and effective classes of attentional mechanism: a global approach which always attends to all source words and a local one that only looks at a subset of source words at a time.
2.
A global approach in which all source words are attended and a local one whereby
only a subset of source words are considered at a time. The former approach resembles the model of (Bahdanau et al., 2015) but is simpler architecturally. The latter can be viewed as an interesting blend between the
hard and
soft attention models proposed in (Xu et al., 2015): it is computationally less expensive than the global model or the
soft attention; at the same time, unlike the hard attention, the local attention is differentiable, making it easier to implement and train.
3. Neural Machine Translation
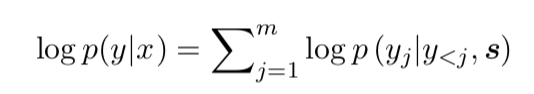
4. Common to these two types of models is the fact that at each time step t in the decoding phase, both approaches first take as input the hidden state
 at the top layer of a stacking LSTM.
The goal is then to derive a context vector
at the top layer of a stacking LSTM.
The goal is then to derive a context vector
 that captures relevant source-side information to help predict the current target word
that captures relevant source-side information to help predict the current target word

5. Global Attention
The idea of a global attentional model is to consider all the hidden states of the encoder when deriving the context vector
 . In this model type, a variable-length alignment vector
. In this model type, a variable-length alignment vector
 , whose size equals the number of time steps on the source side, is derived by comparing the current target hidden state
, whose size equals the number of time steps on the source side, is derived by comparing the current target hidden state
 with each source hidden state
with each source hidden state

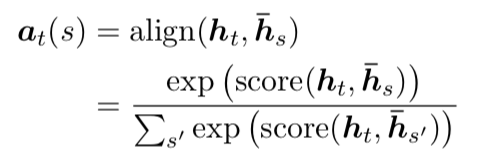
The score is defined like this:
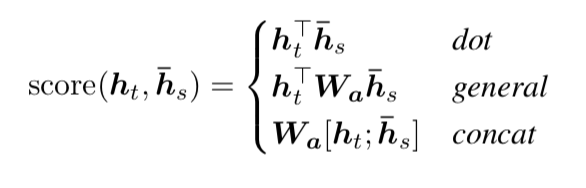
6. Global attentional model
At each time step t, the model infers a
variable-length alignment weight vector at based on the current target state
 and all source states
and all source states
 . A global context vector
. A global context vector
 is then computed as the weighted average, according to
is then computed as the weighted average, according to
 , over all the source states.
, over all the source states.
Given the alignment vector as weights, the context vector
 is computed as the weighted average over all the source hidden states.
is computed as the weighted average over all the source hidden states.
7.
Compare to (Bahdanau et al., 2015):
First, we simply use hidden states
at the top LSTM layers in both the encoder and decoder as illustrated in Figure 2. Bahdanau et
al. (2015), on the other hand, use the
concatenation of the forward and backward source hidden states in the bi-directional encoder and target hidden states in their non-stacking uni-directional decoder.
Second, our computation path is simpler, while Bahdanau et al need to consider
 .
Lastly, Bahdanau et al. (2015) only experimented with one alignment function, the
concat product; whereas we show later that the other alternatives are better.
.
Lastly, Bahdanau et al. (2015) only experimented with one alignment function, the
concat product; whereas we show later that the other alternatives are better.
8. Local Attention
In concrete details, the model first generates an aligned position
 for each target word at time t. The context vector
for each target word at time t. The context vector
 is then derived as a weighted average over the set of source hidden states within the window [
is then derived as a weighted average over the set of source hidden states within the window [
 −D,
−D,
 +D], D is empirically selected.
+D], D is empirically selected.
We consider two variants of the model as below:
Monotonic alignment (local-m) – we simply set
 = t assuming that source and target sequences are roughly monotonically aligned. The alignment vector at is defined according to the equation above.
= t assuming that source and target sequences are roughly monotonically aligned. The alignment vector at is defined according to the equation above.
Predictive alignment (local-p) – instead of assuming monotonic alignments, our model predicts an aligned position as follows:
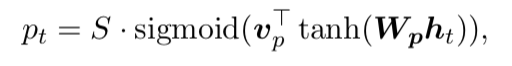
and
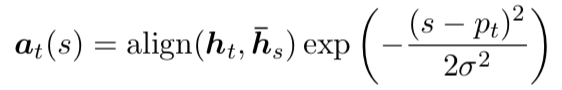
9.
Comparison to (Gregor et al., 2015): have proposed a
selective attention mechanism, very simiar to our local attention, for the image generation
task. Their approach allows the model to select an image patch of varying location and zoom. We, instead, use the same “zoom” for all target positions, which greatly simplifies the formulation and still achieves good performance.
(I dont understand this well.)
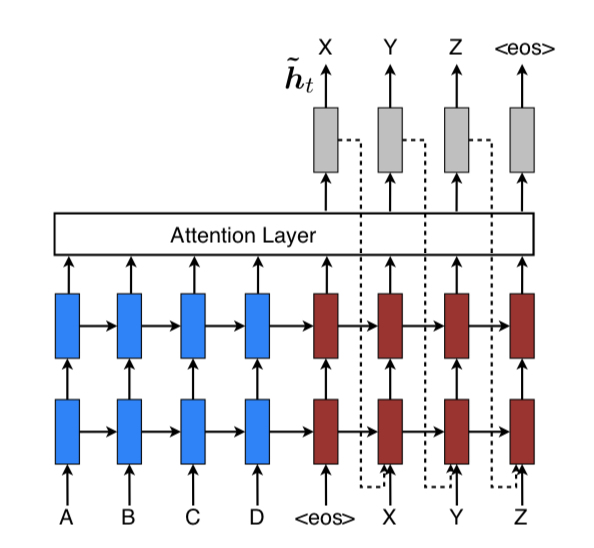
10. Input-feeding Approach
In our proposed global and local approaches, the attentional decisions are made independently, which is suboptimal. Whereas, in standard MT, a
coverage set is often maintained during the translation process to keep track of which source words have been translated. Likewise, in attentional NMTs, alignment decisions should be made jointly taking into account past alignment information. To address that, we propose an
input-
feedingapproach in which attentional vectors
 are
concatenated with inputs at the next time steps as illustrated below. The effects of having such connections are two-fold: (a) we hope to make the model fully aware of previous alignment choices and (b) we create a very deep network spanning both horizontally and vertically.
are
concatenated with inputs at the next time steps as illustrated below. The effects of having such connections are two-fold: (a) we hope to make the model fully aware of previous alignment choices and (b) we create a very deep network spanning both horizontally and vertically.

关注机器学习,深度学习,自然语言处理,强化学习等人工智能新技术。