本文主要介绍我们被 ICLR 2021 会议录用的一篇文章: Zero-shot Synthesis with Group-Supervised Learning。项目主页: webpage,代码和预训练模型已经在 Github 上放出: Code。这项工作受启发于 人脑的想象能力,比如人看到一辆红色的轿车&一辆蓝色的卡车,可以立即想象出一辆蓝色的轿车(即使没有见过)。我们提出了一种区分于现有learning paradigm新的训练范式:组 监督学习 (Group-Supervised Learning),通过 可控的解耦表征学习 (controllable disentangled representation learning)模拟人脑对 知识的因式分解和自由组合,从而实现模拟人脑的想象能力。Group-Supervised Learning 可以通过非常简单的自编码器(Autoencoder)来实现,训练过程只需要 reconstruction loss,简单易收敛,可以实现高质量的 zero-shot synthesis。
一张图概括我们做的事情:Group-Supervised Learning 可以将输入图片(bottom images)进行 可控的解耦(controllable disentanglement)并表示为可以自由组合的不同属性(比如车的种类,姿态,背景; 人的样貌,姿势,表情),然后通过属性的自由组合生成新的图片。
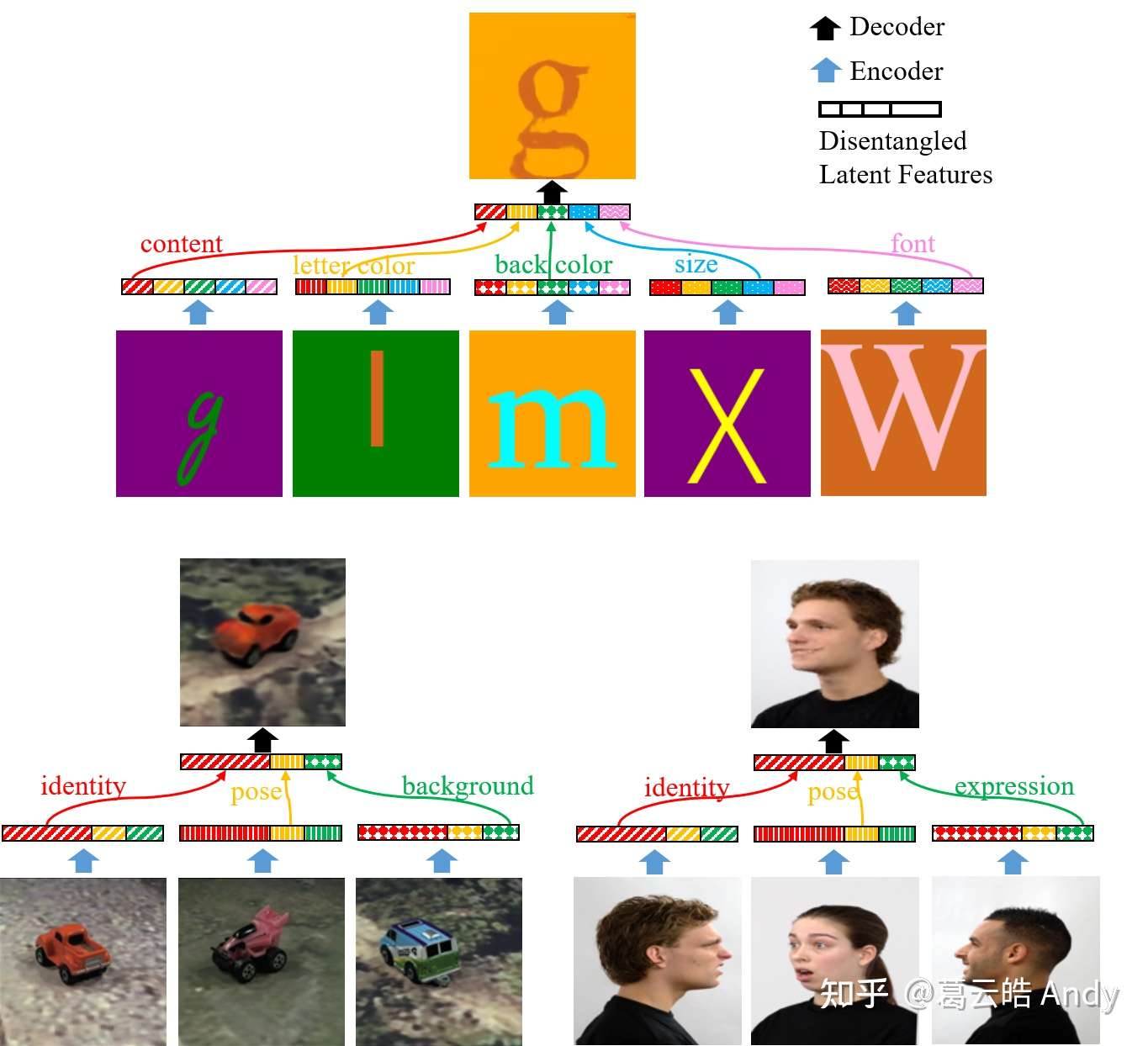
下面我将详细介绍工作的具体内容。
1. Motivation (研究动机)
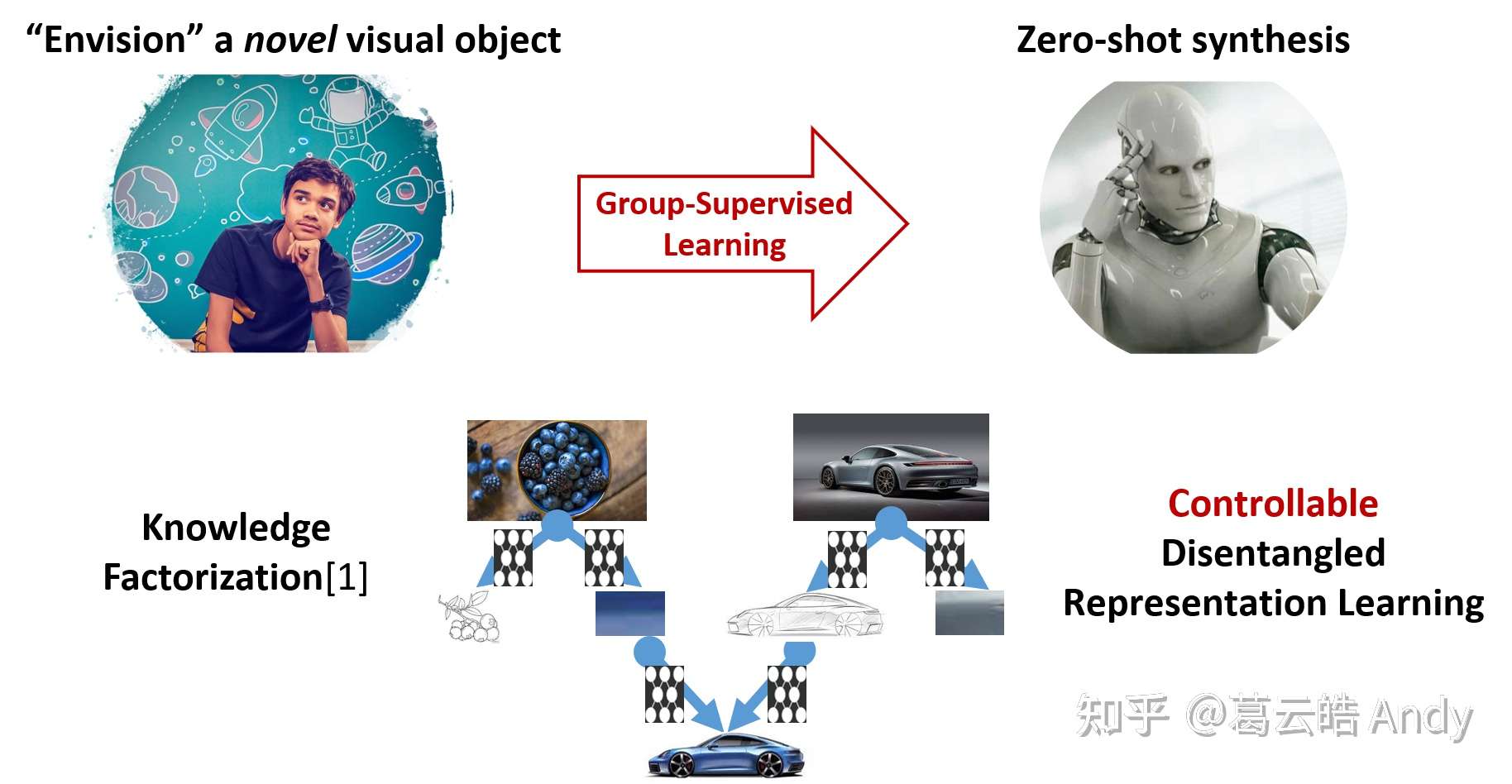
灵长类动物(人类)往往在泛化的任务(generalization task)上表现很好,当看到一个物体,他们可以立即想象出同一个物体在不同属性时的样子,比如不同的 3D pose [1],即使他们从未见过。我们的目标是赋予AI智能体(machines)相似的能力:zero-shot synthesis。我们认为,人类有一个非常重要的能力来帮助想象,那就是将所学的 知识进行因式分解并重新组合。比如图2中,我们可以把见过物体的颜色和轮廓进行分解(蓝莓和跑车),然后通过重新组合想象出未见过的物体(蓝色的跑车)。对于AI智能体,我们可以用神经网络模拟知识的因式分解过程吗?我们给出的答案是可以利用 可控的解耦表征学习 (controllable disentangled representation learning)。我们提出的新的学习框架:组 监督学习 (Group-Supervised Learning)可以帮助这个过程的实现。
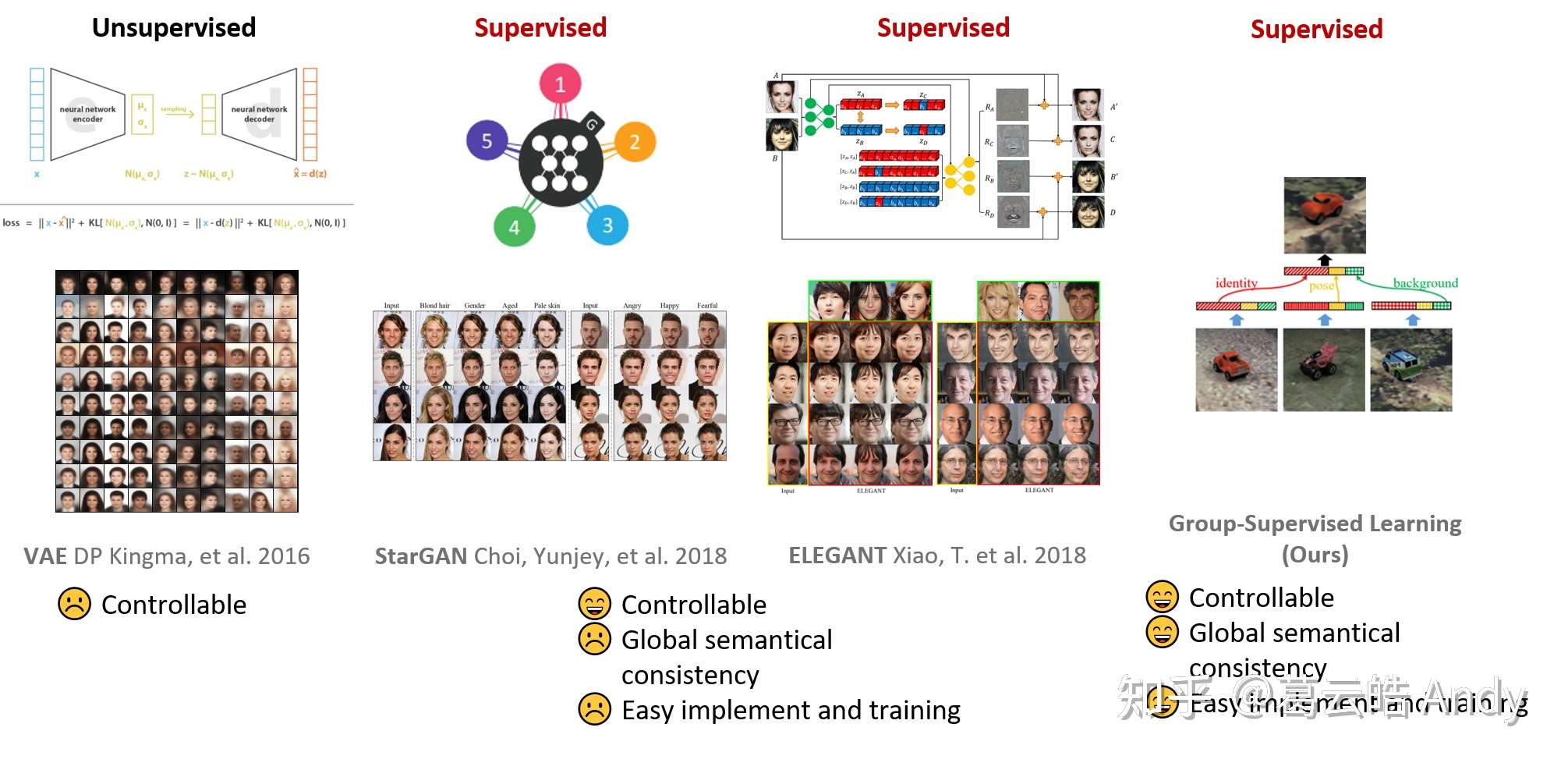
提到解耦 表征学习 (disentangled representation learning),大家首先想到的应该是变分自编码器(VAE),VAEs 可以用无 监督学习 (unsupervised learning)的方式通过添加KL divergence loss 对隐空间的分布进行约束,间接地实现隐空间的解耦表征。然而,在没有数据标签的无监督情况下,VAE很难 控制解耦的过程和结果(比如隐空间是如何划分的,用隐空间中的哪几维存储哪个特定的属性信息)。有监督的学习方法中算法可以获取图片的属性标签,大多数采用基于GAN的生成方法,比如StarGAN [2] 和 ELEGANT [3],他们可以实现属性可控的图像生成,但生成多是局部属性或texture的改变,训练过程和实现较为复杂且不易稳定。为了解决上述问题,我们提出了 一种新的学习范式:组监督学习 ,实现全局多属性可控的图像生成,而且保持全局语义信息的一致(比如转动汽车姿态时作为背景的公路方向会跟着一起转动)。组 监督学习 的实现可以采用简单的自编码器,而且整个训练只需要reconstruction loss,稳定且收敛快。
2 Problem Statement and Approach(问题定义和解决方法)
要实现 属性可控的解耦,关键在于如何达到可控,也就是我们要精确控制每个属性信息的流动过程。利用数据的属性标签进行监督是必要的,但监督过程是仁者见仁的:是将数据集中的每个样本单独使用?还是将每个样本的属性以及 属性关系进行有机的表示?我们选择了后者,所谓 组 监督学习 ,字面理解就是每次输入的是 一组样本,一组内部关系得到有机表示的样本,通过在隐空间中的属性信息交换(swap)和组合(recombination),挖掘样本之间的相似性(similarity mining)作为监督信息,达到可控的解耦表征。
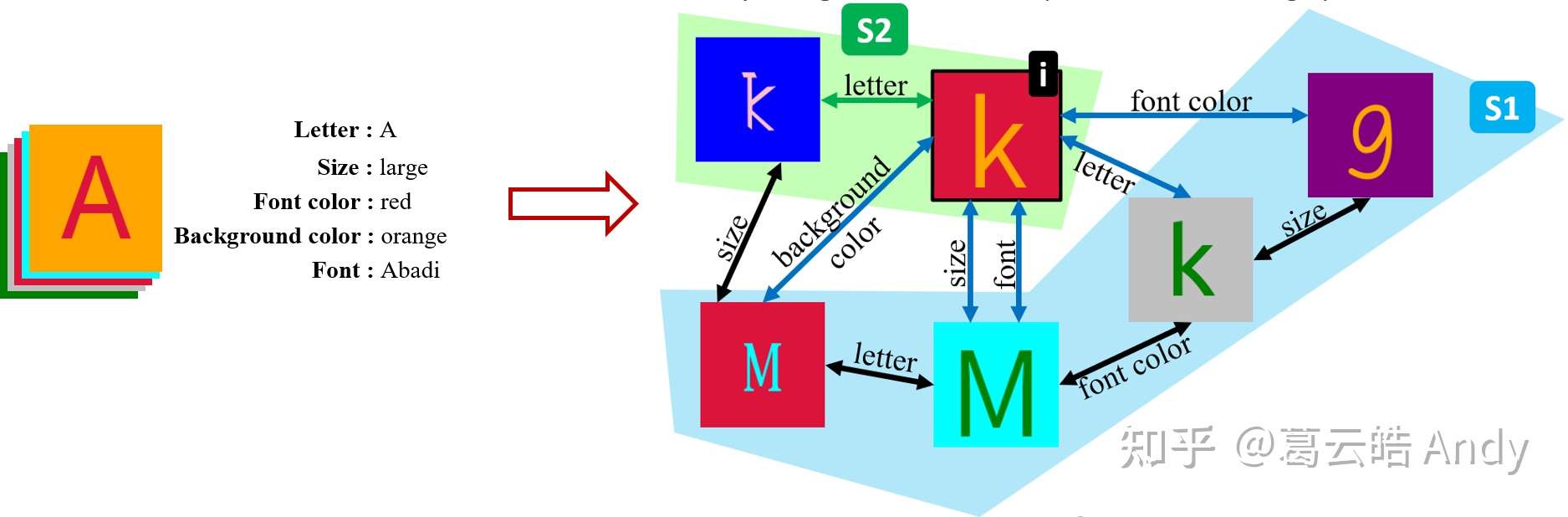
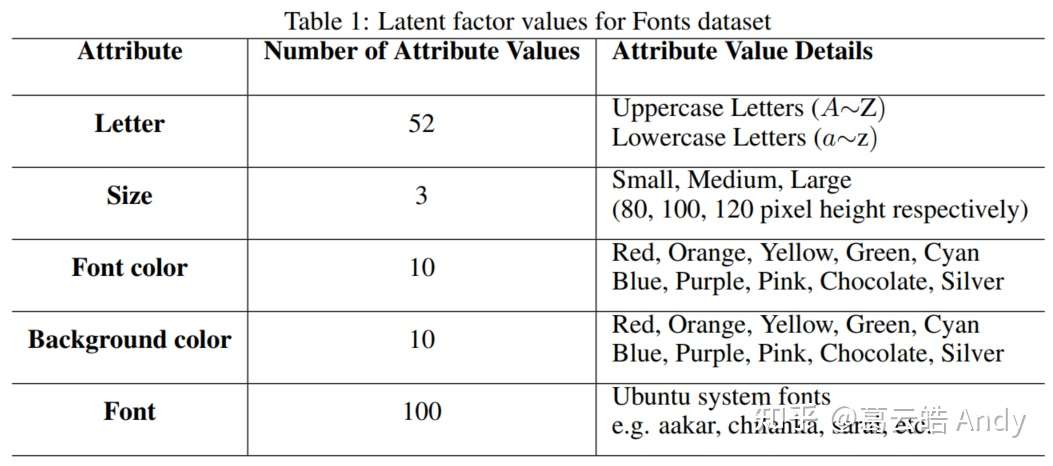
如图4所示,给定一个数据集以及每个样本的属性标签(以Fonts dataset [4] 为例,每张字母图片都有五个属性:字母,大小,字母颜色,背景颜色,字体),我们将其表示为Multi-Graph,Graph中的点表示数据集中的不同样本,边表示样本之间共享的属性标签(比如两个样本具有相同的字母颜色,就会有一条Font color的边连接两个样本),我们称之为Multi-Graph的原因是点之间共享的属性标签可能有多个,所以区别于传统graph(两点之间只有一条边),Multi-Graph的两点之间可以有多条边,且边的数目是由两点之间共享属性的数目决定的。将数据集表示为Multi-Graph的 原因是希望能更好的挖掘数据之间属性的异同,从而更好的指导属性可控的解耦表征学习 。
接下来我们提供了组 监督学习 基于自编码器的 一种实现 Group-Supervised Zero-shot synthesis Network (GZS-Net),以ilab-20M [5] dataset为例详细介绍 实现可控解耦的训练过程。
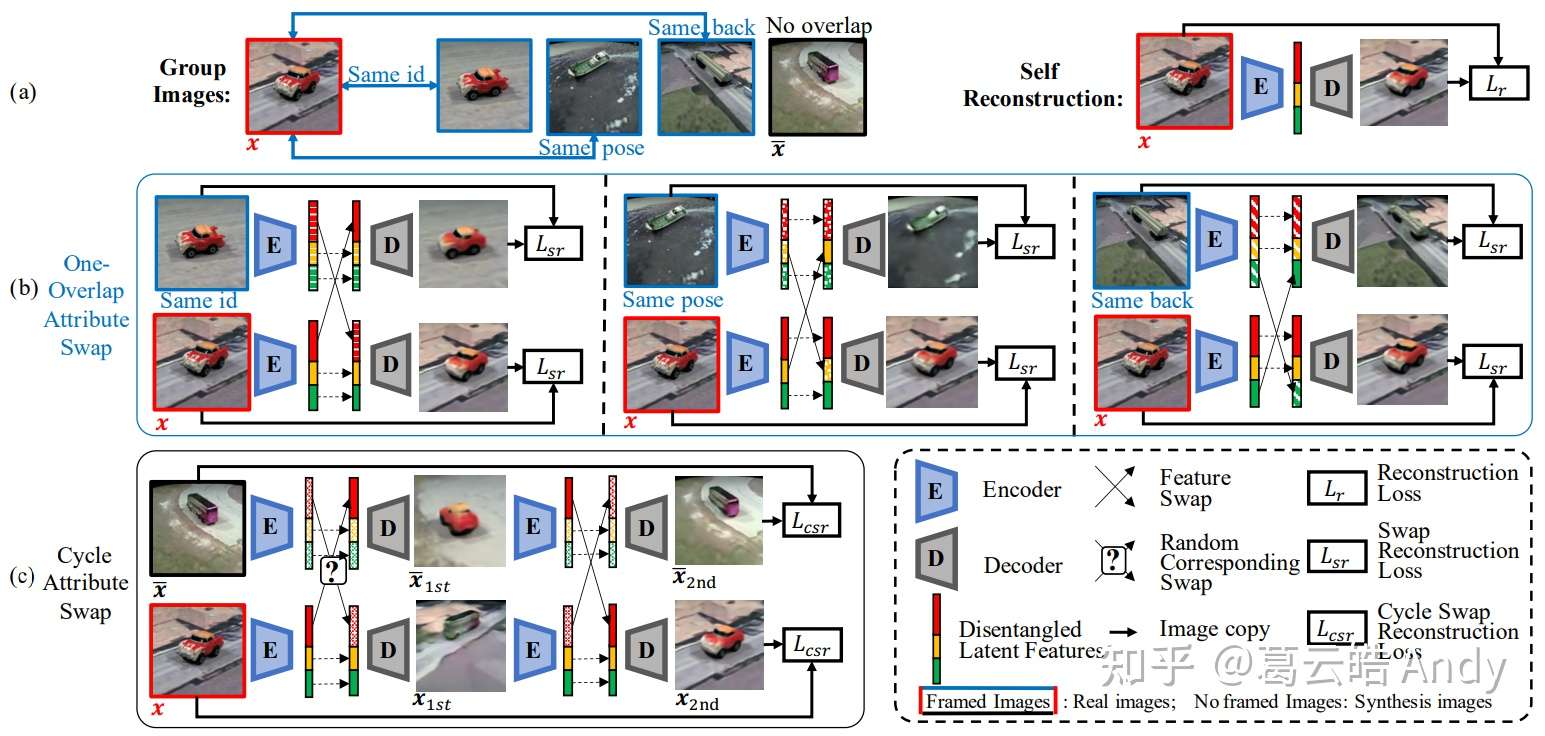
GZS-Net 的网络结构是一个简单的自编码器:包括一个编码器(encoder E)和一个解码器(decoder D)。输入是一个multi-graph,损失函数由三部分组成,均为reconstruction loss(pixels wise L2 / L1 loss): self reconstruction Loss, swap reconstruction 和 cycle swap reconstruction loss,三个损失项分别对应三个训练步骤:
Step 1 Self reconstruction
如图5,一组图片以Multi-Graph的形式作为输入:其中红框中的图片为x,蓝色框中的图片与x仅有一组属性值相同并由蓝色的边所表示,黑色框中的图片x-bar与x没有任何相同属性值。首先将每张图片输入到 E 和 D中按照自编码器的训练方式用reconstruction loss 训练 GZS-Net。这个步骤可以看作是一个正则项,保证输入的图片所有的信息都可以被 E 编码到 latent vector中,避免信息丢失。
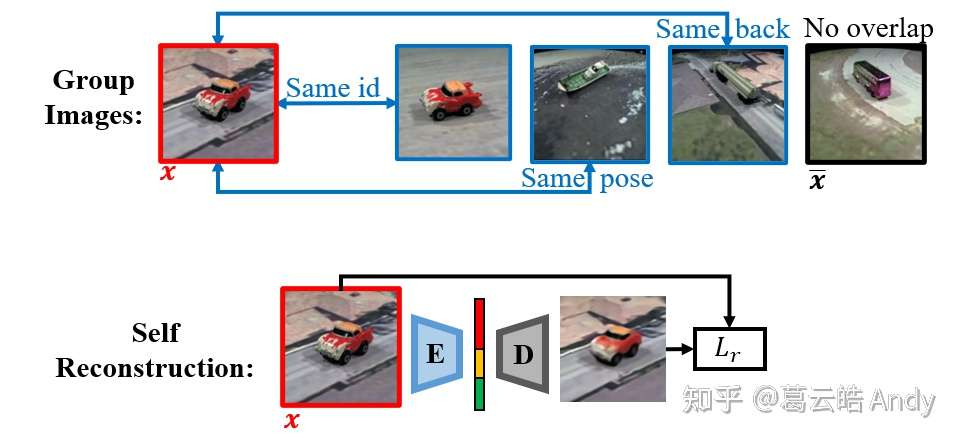
接下来,为了实现可控的解耦,我们 先在latent vector中预定义每个属性的编码位置:红色编码(储存)identity 信息,黄色编码姿态信息,绿色编码背景信息。 然后通过接下来 Step 2 和 Step 3 的基于multi-graph的属性交换与约束实现预定义的可控解耦。
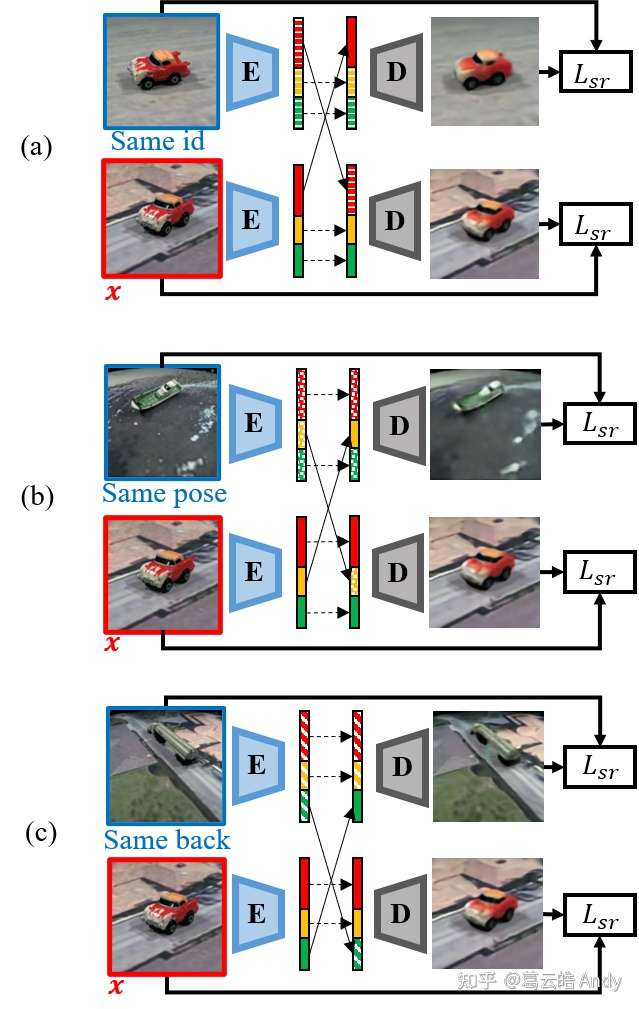
Step 2 One Overlap Attribute Swap
如图6(a),从multi-graph中取一条属性值为id的边,将边连接的两个id属性相同的图片分别通过 E 得到 他们的latent vector,然后我们将他们相同的属性(id)预划分的区域(红色)进行交换,得到两个新的latent vector,并将他们分别通过 D 生成两张新的图片。 因为我们希望红色部分编码id的信息而两张图又具有相同的id,所以交换id部分过后生成的图片应该与原图相同,所以我们用reconstruction loss进行约束。相似的,我们接着取属性为姿态(图6 b)和背景(图6 c)的边,将他们连接的点做同样的操作:编码,交换相同属性值区域,约束生成的图片与原图相同。 这一过程利用multi-graph图片之间的关系,使网络学习如何挖掘图片之间high-level属性的相似性,并通过交换实现可控的解耦表征。Note:在这一步,我们需要swap所有 attribute 对应的 latent 区域,即红,黄,绿三部分都需要交换,以此来避免网络将所有信息存储到不被交换的区域来cheat。
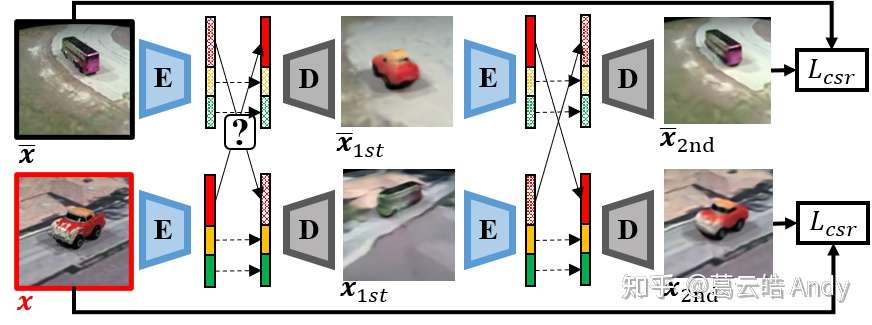
Step 3 Cycle Attribute Swap
最后一步是选取没有相同属性值的两张图片,通过 E 得到 latent vector 后,我们随机选取一个属性进行交换,生成两张没有ground truth的图片;然后我们再将他们通过 E 把刚刚交换过的属性再交换回来,约束两次交换后生成的图片与原始输入的图片相同。这一步骤 间接的约束了可控的属性解耦:如果中间步骤生成的图片质量很差,或者属性值不是预期的样子,第二次交换过后生成的图片会与input图片有较大差距。
最后用一张图表示整个GZS-Net的训练过程。可以看到整个训练我们只用了reconstruction loss,框架是基础的 Autoencoder,容易实现,训练稳定且收敛快。
下图是算法的伪代码。Note:在released code 中我们提供了一种更为简单的训练过程:在Step 2 One-Overlap attribute Swap时(1)不需要两张图片只有一个attribute 相同,只要需要交换的attribute相同即可,其他attribute不做限制。(2)不需要有一张图片x出现在所有属性的交换过程中,不同属性之间可以选用不同的满足要求的图片。详情请见 code。

3 Experiments and Results (实验和结果)
(a)定性实验
下图展示了在 ilab-20M 数据集上进行零镜头生成(zero-shot synthesis)的结果,我们希望解耦 ilab-20M 中的三个属性:车辆id(identity),姿态和背景。在生成过程中,输入是每个目标属性的提供者,我们希望从每个属性提供者中提取目标属性值,并将它们重新组合,生成目标图片。红色虚线框中展示的是我们的 GZS-Net 的结果,包括消融实验(ablation study)。可以看到生成的图像可以满足query式可控生成的需求,而且生成的场景能够保证语义的一致(当车辆作为前景进行旋转时,道路作为背景会跟着进行旋转)。baseline有两大类,一类是基于GAN的算法:StarGAN 和 ELEGANT,另一类是 Autoencoder+Direct Supervision(AE+DS)即直接在autoencoder 的隐空间中加入对应属性分类器当作监督训练的模型。我们的输入图片的格式会根据不同baseline算法的生成步骤需求做出调整。

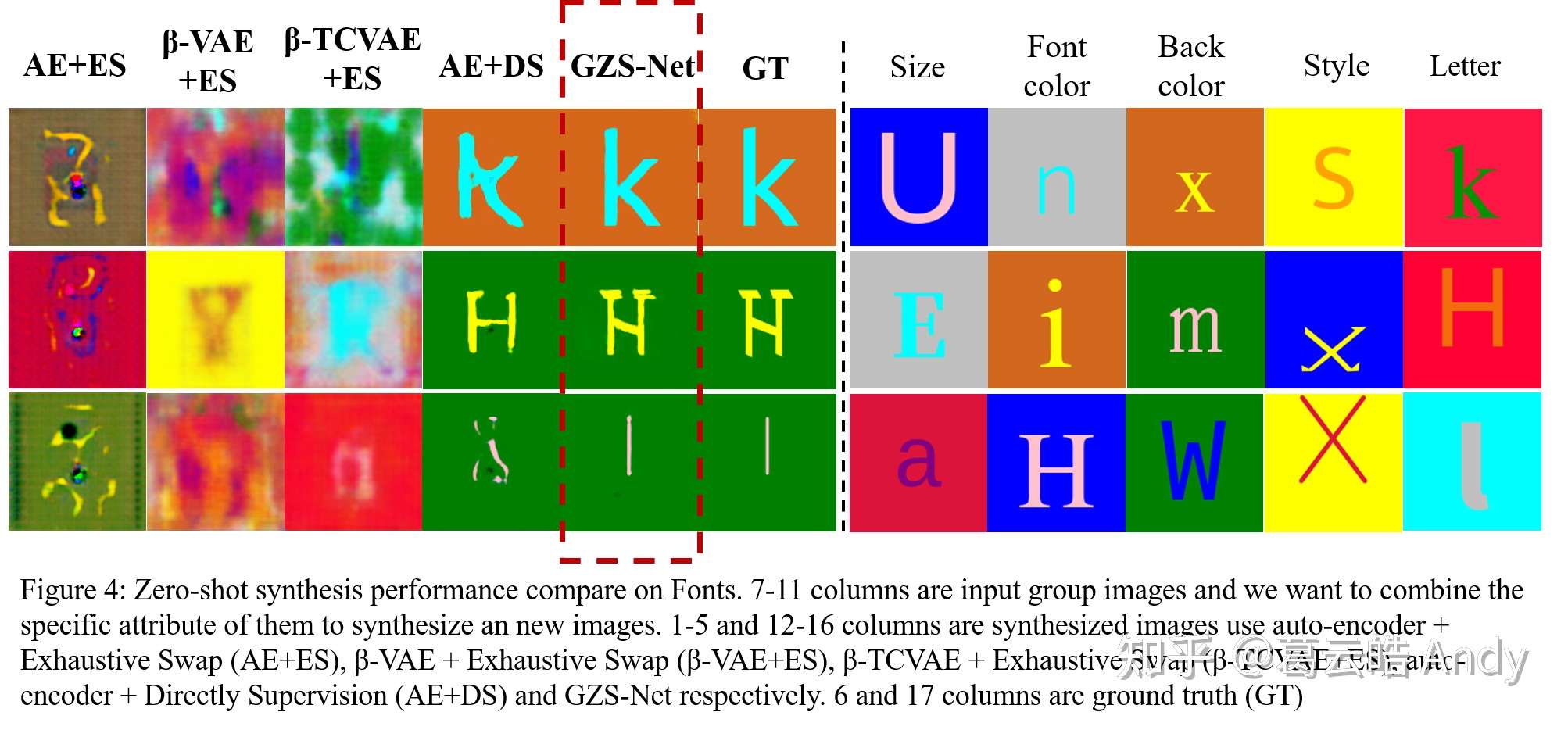
下图展示了在 Fonts 数据集上进行零镜头生成(zero-shot synthesis)的结果,我们希望解耦 Fonts 中的五个属性:字母,字体(Font Style),背景颜色,字母颜色和字母大小。同样生成时每一个目标attribute有一个提供者,我们希望从每个属性提供者中提取目标属性值,并将它们重新组合,生成目标图片。红色虚线框展示的是我们的 GZS-Net 的结果;baseline方法中还包括基于VAE的算法,在β-VAE 和 β-TCVAE的基础上做 Exhaustive Search(ES)使其适应controllable synthesis task(细节请见paper)。
下图展示了在 RaFD [6] 数据集上进行零镜头生成(zero-shot synthesis)的结果,我们希望解耦 RaFD 中的三个属性:identity,pose 和 expression。

(b)定量实验
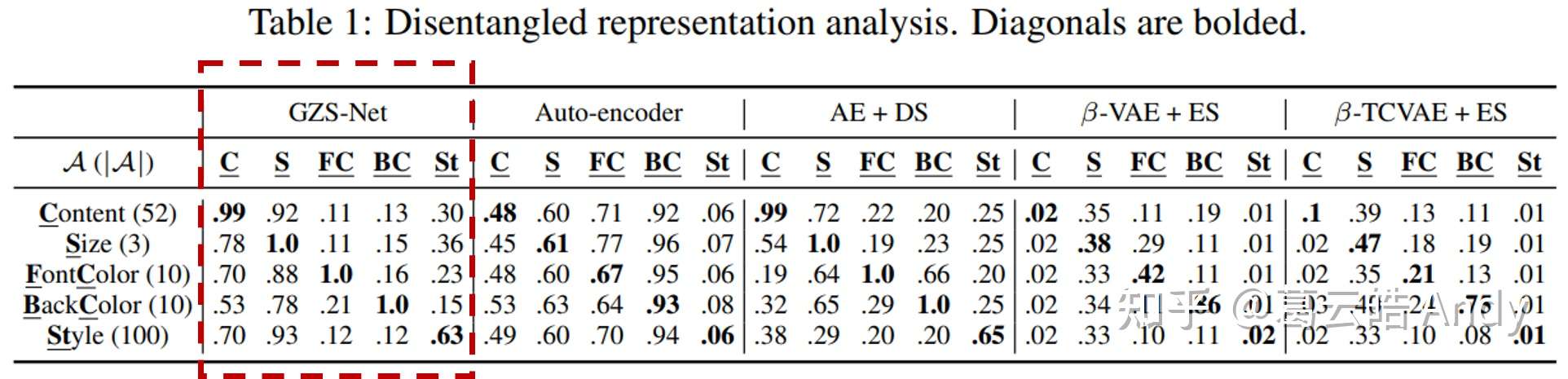
第一个实验是用解耦属性之间的互相预测(co-prediction)来定量分析解耦表征的效果。为了分析解耦效果,我们会问以下问题:我们可以用latent vector中一个属性编码的信息来预测该属性的label吗?我们可以用它来预测 其他属性的label吗?在 完美解耦表征的情况下,我们永远会给第一个问题 肯定的回答而给第二个问题 否定的回答。如下图,我们计算了模型关于属性的confusion matrix:使用每个属性在latent vector中对应维度的信息预测所有属性的label。一个完美解耦的模型应该接近Identity 矩阵。我们的模型在对角线有比较高的准确率,在非对角线准确率较低。
第二个实验是在Fonts 数据集(能提供所有可能的属性组合)中计算生成图像与 ground truth之间的平均MSE 和 PSNR从而定量地分析生成图片质量。

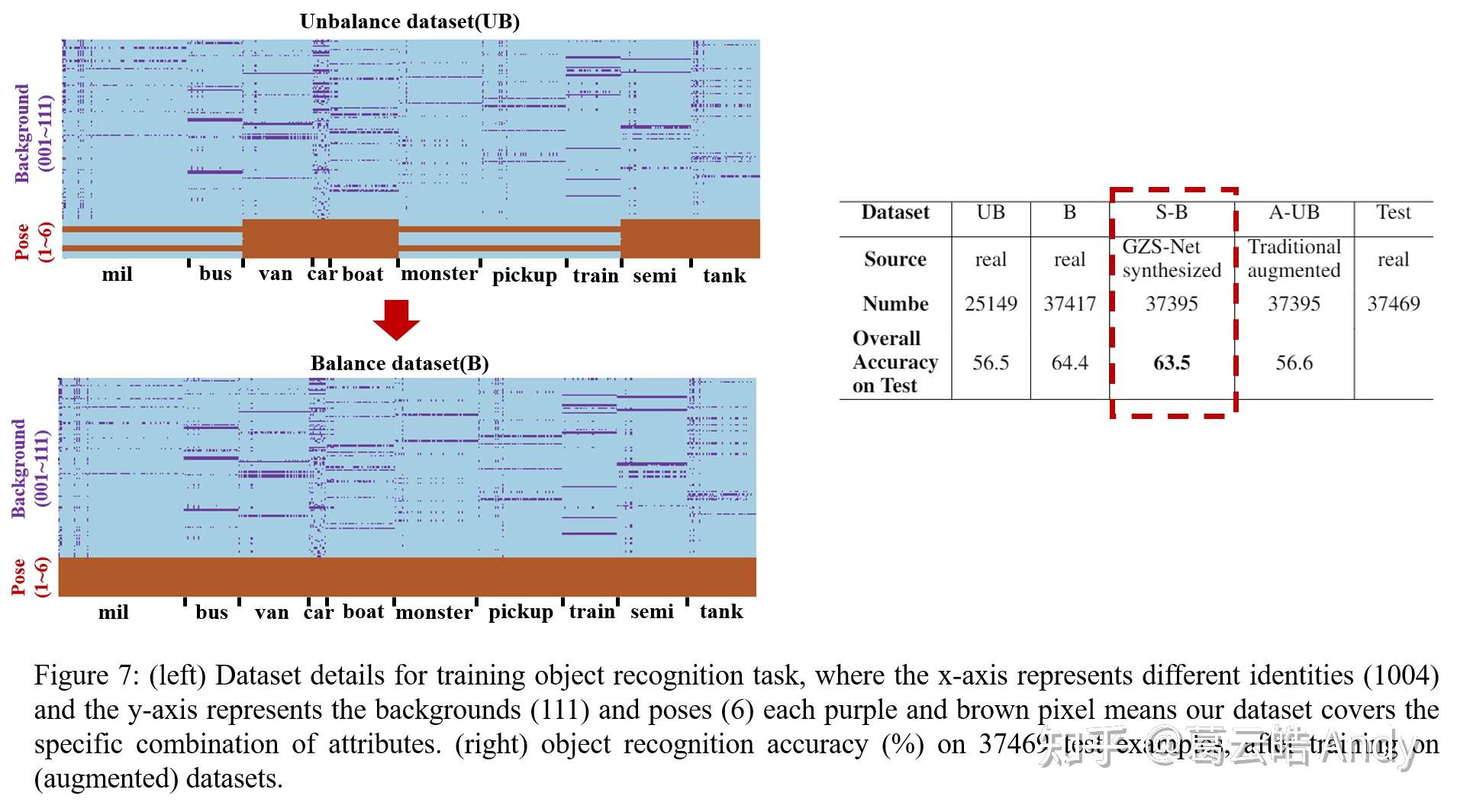
第三个实验是把 Group-Supervised Learning 用作数据增强方法,看能否将原本unbalance 的数据集增强为balance的数据集,并提升下游分类模型的准确率。可以看到数据增强效果明显好于传统的数据增强算法并提升了分类模型的准确率。
4 Fonts:一个新的开源数据集
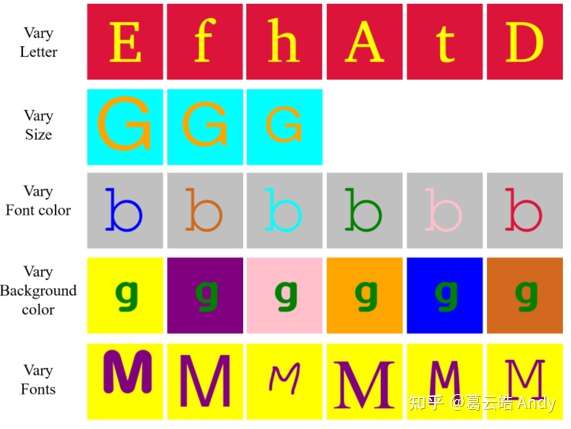
 Fonts 是我们开源的一个属性可控的 RGB 图像数据集,每张图片(尺寸为128*128)包括一个用五个独立属性渲染生成的字母,五个属性分别为:字母,大小,字母颜色,背景颜色和字体。下图展示了一些例子。数据集包含了提出属性的所有可能的组合,共计1.56 million 张。
我们提出Fonts数据集的首要目的是为了给解耦表征学习
和零镜头生成的研究者提供一个可以快速验证和迭代想法的平台。
Fonts 是我们开源的一个属性可控的 RGB 图像数据集,每张图片(尺寸为128*128)包括一个用五个独立属性渲染生成的字母,五个属性分别为:字母,大小,字母颜色,背景颜色和字体。下图展示了一些例子。数据集包含了提出属性的所有可能的组合,共计1.56 million 张。
我们提出Fonts数据集的首要目的是为了给解耦表征学习
和零镜头生成的研究者提供一个可以快速验证和迭代想法的平台。
除了上述的五个属性,我们还拓展了Fonts-v2版本,增加了简单的单词以及新的属性:位置,旋转和纹理,示例请见下图。

目前 Fonts的所有生成代码已开源,欢迎来我们的网站下载数据集和代码:
5 Conclusion (总结)
总结来说,这项工作的要点在于:(1)提出一种新的学习范式——组 监督学习 (Group-Supervised Learning)可以模仿人脑的想象力并赋予AI智能体zero-shot synthesis的能力。(2)组 监督学习 以一组图片作为输入,通过挖掘图片之间属性的相关关系 实现可控的解耦表征和自由组合,模拟 人类对知识的因式分解和重新组合。(3)作为一种新的学习范式,组 监督学习 容易实现,训练稳定可快速收敛,可以帮助不同的下游任务。定量和定性的分析了在属性可控生成,解耦 表征学习 与数据增强方向的应用。
更多细节请参考原 paper,欢迎大家follow我们的工作:)
@inproceedings{ge2021zeroshot, title={Zero-shot Synthesis with Group-Supervised Learning}, author={Yunhao Ge and Sami Abu-El-Haija and Gan Xin and Laurent Itti}, booktitle={International Conference on Learning Representations}, year={2021}, url={https://openreview.net/forum?id=8wqCDnBmnrT} }
如果有任何问题,欢迎大家留言或者给我发邮件讨论,最后附上我的主页链接:
https://gyhandy.github.io/gyhandy.github.io
参考
- ^Logothetis et al., 1995. https://www.sciencedirect.com/science/article/pii/S0960982295001084
- ^StarGAN Choi, Yunjey, et al. 2018 https://arxiv.org/pdf/1711.09020.pdf
- ^ELEGANT Xiao, T. et al. 2018 https://arxiv.org/pdf/1803.10562.pdf
- ^Fonts dataset http://ilab.usc.edu/datasets/fonts
- ^ilab-20M http://ilab.usc.edu/publications/doc/Borji_etal16cvpr.pdf
- ^RaFD dataset http://www.socsci.ru.nl:8180/RaFD2/RaFD#:~:text=The%20RaFD%20is%20a%20high,surprise%2C%20contempt%2C%20and%20neutral