常用的表格检测识别方法-表格区域检测方法(上)
- 2023-05-26 12:41:00
- 刘大牛 转自文章
- 745
常用的表格检测识别方法
表格检测识别一般分为三个子任务:表格区域检测、表格结构识别和表格内容识别。本章将围绕这三个表格识别子任务,从传统方法、深度学习方法等方面,综述该领域国内国外的发展历史和最新进展,并提供几个先进的模型方法。
3.1 表格区域检测方法
表格检测已经被研究了一段较长的时间。研究人员使用了不同的方法,可以分为如下:
1.基于启发式的方法
2.基于机器学习的方法
3.基于深度学习的方法
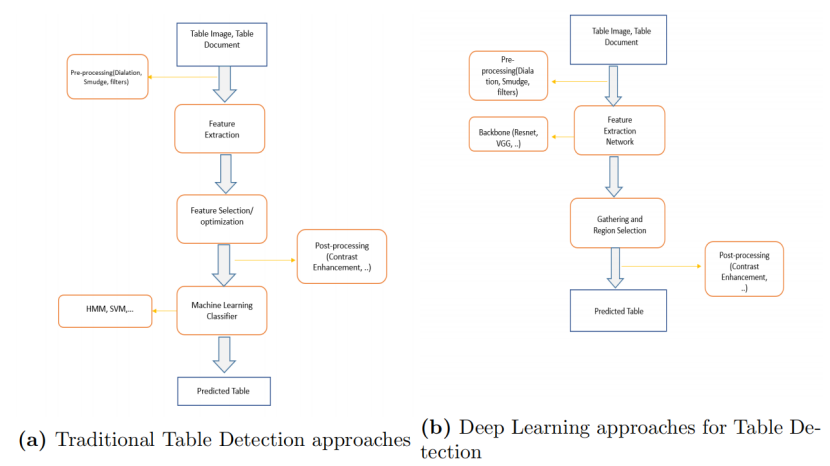
基于启发式的方法,主要用于20世纪90年代、2000年代和2010年初。他们使用了不同的视觉线索,如线条、关键词、空间特征等,来检测表格。
Pyreddy等人提出了一种使用字符对齐、孔和间隙来检测表格 的方法。Wang等人使用了一种统计方法来根据连续单词之间的距离来检测表线。将水平连续的单词与垂直相邻的线分组起来,提出候选表实体。Jahan等人提出了一种使用单词间距和线高的局部阈值来检测表格区域的方法。
Itonori提出了一种基于规则的方法,通过文本块排列和规则行位置来定位文档中的表格。 Chandran和Kasturi开发了另一种基于垂直和水平线的表格检测方法。Wonkyo Seo等人使用连接点(水平线和垂直线的交点)检测进行进一步处理。
Hassan等人通过分析文本块的空间特征来定位和分割表格。Ruffolo等人介绍了PDF-TREX,这是一种用于单列PDF文档中的表格识别的启发式自下而上的方法。它使用页面元素的空间特征来将它们对齐和分组为段落和表格。Nurminen提出了一套启发式方法来定位具有公共对齐的后续文本框,并确定它们作为一个表格的概率。
Harit等人提出了一种基于唯一表起始和尾部模式识别的表格检测技术。Tupaj等人提出了一种基于OCR的表格检测技术。该系统基于关键字搜索类似表格的行序列,上述方法在具有统一布局的文档上效果比较好。
国内的表格区域检测研究起步较晚,启发式方法较少。其中,具有代表性的是Fang等人提出的基于表格结构特征和视觉分隔符的方法。该方法以PDF文档为输入,分四步进行表格检测:PDF解析,页面布局分析,线条检测和页面分隔符检测,表格检测。在最后的表格检测部分中,通过对上一步检测出的线条和页面分隔符进行分析得到表格位置。然而,启发式规则需要推广到更广泛的表格种类,并不真正适合通用的解决方案。因此,开始采用机器学习方法来解决表检测问题。
基于机器学习的方法在2000年代和2010年代很常见。
Kieninger等人通过对单词片段进行聚类,应用了一种无监督的学习方法。Cesarini等人使用了一种改进的XY树监督学习方法。Fan等人使用有监督和无监督的方法进行PDF文档中的表格检测。Wang和Hu 将决策树和SVM分类器应用于布局、内容类型和词组特征。T. Kasar等人使用结点检测,然后将信息传递给SVM分类器。Silva等人在视觉页面元素(隐马尔可夫模型)的顺序观察上应用联合概率分布,将潜在的表线合并到表中。Klampfl等人比较了两种来自数字科学专题文章的无监督表识别方法。Docstrum算法应用KNN将结构聚合成线,然后使用线之间的垂直距离和角度将它们组合成文本块。该算法是在1993年设计的,比本节中提到的其他方法要早。
F Shafait 提出了一种有用的表识别方法,该方法在具有相似布局的文档上表现良好,包括商业报告、新闻故事和杂志页面。Tesseract OCR引擎提供了该算法的一个开源实现。
随着神经网络的兴趣,研究人员开始将它们应用于文档布局分析任务中。最初,它们被用于更简单的任务,如表检测。后来,随着更复杂的架构的发展,更多的工作被放到表列和整体结构识别中。
A Gilani [《Table detection using deep learning》]展示了如何使用深度学习来识别表格。文档图片最初是按照文中提出的方法进行预处理的。然后,这些照片被发送到一个区域候选网络中进行表格测试,然后是一个完全连接的神经网络。该方法对各种具有不同布局的文档图片非常精确,包括文档、研究论文和期刊。
D Prasad [《An approach for end to end table detection and structure recognition from image-based documents》]提出了一种解释文档图片中的表格数据的自动表格检测方法,主要需要解决两个问题:表格检测和表格结构识别。使用单一的卷积神经网络(CNN)模型,提供了一个增强的基于深度学习的端到端解决方案,用于处理表检测和结构识别的挑战。CascadeTabNet是一个基于级联掩码区域的CNN高分辨率网络(Cascade mask R-CNN HRNet)的模型,可以同时识别表区域和识别这些表格中的结构单元格。
SS Paliwal [《Tablenet: Deep learning model for end-to-end table detection and tabular data extraction from scanned document images》]提出了一种新的端到端深度学习模型,可用于表格检测和结构识别。为了划分表格和列区域,该模型使用了表格检测和表结构识别这两个目标之间的依赖关系。然后,从发现的表格子区域中,进行基于语义规则的行提取。
Y Huang [《A yolo-based table detection method》]描述了一种基于YOLO原理的表格检测算法。作者对YOLOv3提供了各种自适应改进,包括一种锚定优化技术和两种后处理方法,以解释文档对象和真实对象之间的显著差异。还使用k-means聚类进行锚点优化,以创建更适合表格而不是自然对象的锚点,使他们的模型更容易找到表格的精确位置。在后处理过程中,将从投影的结果中删除额外的空白和有噪声的页面对象。
L Hao [《A table detection method for pdf documents based on convolutional neural networks》]提供了一种基于卷积神经网络的PDF文档中检测表格的新方法,这是目前最广泛使用的深度学习模型之一。该方法首先使用一些模糊的约束来选择一些类似表的区域,然后构建和细化卷积网络,以确定所选择的区域是否为表格。此外,卷积网络立即提取并使用表格部分的视觉方面特征,同时也考虑了原始PDF文档中包含的非视觉信息,以帮助获得更好的检测结果。
SA Siddiqui [《Decnt: Deep deformable cnn for table detection》]为检测文档中的表格提供了一种新的策略。这里给出的方法利用了数据的潜力来识别任何排列的表。该方法直接适用于图像,使它普遍能适用于任何格式。该方法采用了可变形CNN和faster R-CNN/FPN的独特混合。由于表格可能以不同的大小和转换(方向)的形式出现,传统的CNN有一个固定的感受野,这使得表格识别很困难。可变形卷积将其感受野建立在输入的基础上,使其能够对其感受野进行改造以匹配输入。由于感受野的定制,网络可以适应任何布局的表格。
N Sun [《Faster r-cnn based table detection combining corner locating》]提出了一种基于Faster R-CNN的表检测的寻角方法。首先使用Faster R-CNN网络来实现粗表格识别和角定位。然后,使用坐标匹配来对属于同一表格的那些角进行分组。不可靠的边同时被过滤。最后,匹配的角组微调并调整表格边框。在像素级,该技术提高了表格边界查找的精度。
I Kavasidis[《A saliency-based convolutional neural network for table and chart detection in digitized documents》]提出了一种检测表格和图表的方法,使用深度cnn、图形模型和 saliency ideas的组合。M Holecek[《Table understanding in structured documents》]提出了在账单等结构化文档中利用图卷积进行表格理解的概念,扩展了图神经网络的适用性。在研究中也使用了PDF文档,研究结合行项表格检测和信息提取,解决表格检测问题。任何字符都可以快速识别为行项或不使用行项技术。在字符分类之后,表格区域可以很容易地识别出来,因为与账单上的其他文本部分相比,表格线能够相当有效地区分。
A Casado-Garcıa[《The benefits of close-domain fine-tuning for table detection in document images》]使用了目标检测技术,作者已经表明,在进行了彻底的测试后发现,从一个更近域进行微调可以提高表格检测的性能。作者利用了Mask R-CNN、YOLO、SSD和 Retina Net结合目标检测算法。该研究选择了两个基本数据集, TableBank和PascalVOC。
X Zheng [《Global table extractor (gte): A framework for joint table identification and cell structure recognition using visual context》]提供了全局表格提取器(GTE),这是一种联合检测表格和识别单元结构的方法,可以在任何对象检测模型之上实现。为了利用单元格位置预测来训练他们的表网络,作者开发了GTE-Table,它引入了一种基于表格固有的单元格约束限制的新惩罚。一种名为GTE-Cell的新型分层单元识别网络利用了表格样式。此外,为了快速、低成本地构建一个相当大的训练和测试数据语料库,作者开发了一种方法来自动分类现有文本中的表格和单元格结构。
Y Li[《A gan-based feature generator for table detection》]提供了一种新的网络来生成表格文本的布局元素,并提高规则较少的表格的识别性能。生成对抗网络(GAN)与该特征生成器模型是类似的。作者要求特征生成器模型为规则约束严格和规则松散的表格提取可比较的特征。
DD Nguyen [《a fully convolutional network for table detection and segmentation in document images》]引入了TableSegNet,一个完全卷积的网络,设计紧凑,可以同时分离和检测表。TableSegNet使用较浅的路径来发现高分辨率的表格位置,而使用较深的路径来检测低分辨率的表格区域,将发现的区域分割成单独的表格。TableSegNet在整个特征提取过程中使用具有广泛内核大小的卷积块,并在主输出中使用一个额外的表格边界类,以提高检测和分离能力。
D Zhang [《Yolo-table: disclosure document table detection with involution》]提出了一种 YOLO-table-based的表格检测方法。为了提高网络学习表格空间排列方面的能力,作者将退化纳入了网络的核心,并创建了一个简单的FPN网络来提高模型的有效性。这项研究还提出了一种基于表格的增强技术。
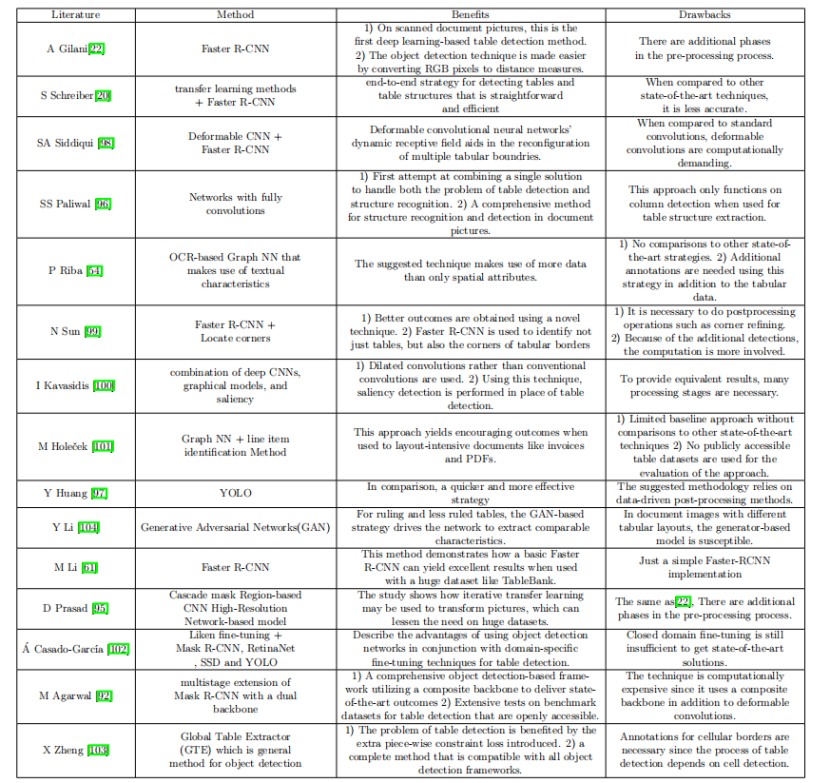
下图是几种基于深度学习的表格检测方法的优缺点的比较。
3.1.1 先进的表格区域检测模型
DeCNT
2018年的论文《DeCNT: Deep Deformable CNN for Table Detection》提出了一种新的表格检测方法,利用深度神经网络的潜力。传统的表格检测方法依赖于容易出错且特定于数据集的启发式方法。相比之下,本方法利用了数据识别任意布局的表格的潜力。以前的大多数表格检测方法只适用于pdf,而所提出的方法直接适用于图像,使其普遍适用于任何格式。本方法采用了可变形CNN和faster R-CNN/FPN的独特混合。由于表格可能以不同的大小和转换(方向)的形式出现,传统的CNN有一个固定的感受野,这使得表格识别很困难。可变形卷积将其感受野建立在输入的基础上,使其能够对其感受野进行改造以匹配输入。由于感受野的定制,网络可以适应任何布局的表格。
DeCNT算法原理:
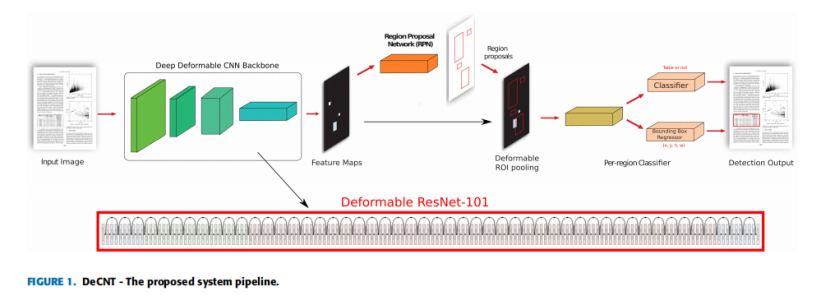
框架由可变形的CNN与faster R-CNN/FPN 的新组合组成,如图1所示。卷积神经网络是一种自动特征提取器,具有自动发现对手头任务有用的特征的能力。这种特征的自动提取是基于层的层次结构,其中初始层提取原始特征,如边缘和梯度,而层次结构顶部的层提取非常抽象的特征,如完整的对象或它的一些突出部分。这种在层次结构中的遍历导致了在原始输入图像中一个特定神经元的有效感受野的增加。传统的二维卷积运算可以用数学方法表示为:
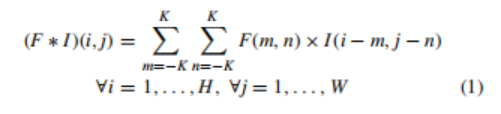
其中*为卷积运算,F为滤波器,I为图像,K定义为FilterSize/2,H为图像高度,W为图像宽度,i,j定义执行卷积运算的位置。
在一个给定的卷积层中,所有神经元的有效感受野是相同的。这个属性对于位于层次结构顶部的层存在问题,因为在这些层中,不同的对象可能会以任意尺度以及任意转换出现。这些转换的存在需要根据神经元的输入动态地适应神经元的感受野的能力。因此,作者为faster R-CNN/FPN模型配备了一个可变形的CNN,而不是传统的CNN,其神经元并不局限于一个预定义的感受野。每个神经元可以根据输入产生显式偏移来改变其感受野,这些偏移本身依赖于前面的特征图。这允许卷积层滤波器通过调节输入本身的感受野来适应不同的尺度和转换。这个可变形的卷积层如图2所示,其中添加了一组卷积层来生成图像中每个位置的滤波器偏移量。由于表可以以任意的比例以及任意变换(方向等),可变形卷积运算对于表的检测任务特别有用。可变形的二维卷积运算包含额外的偏移量,这在数学上可以表示为:
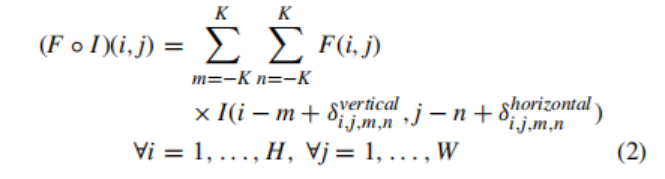

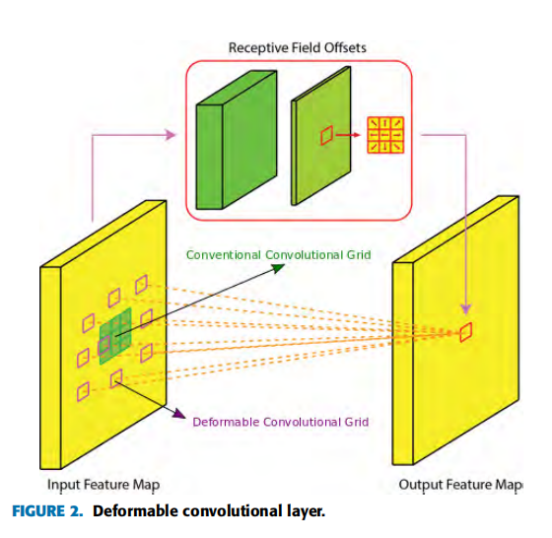

其中nm,n为bin(m,n)中的像素数。如果有C输入特征映射,那么来自该层的总体输出将是k × k × C,它将被提供给分类头。
可变形的roi池,就像卷积对应的池一样,为roi池层增加了一个偏移量,以便该层可以适应给定输入的感受野。这一点可以写成:
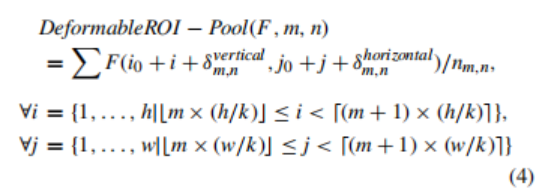

由于在可变形的卷积层中生成显式偏移来转换每个神经元的感受野,作者在图3中可视化了特定可变形卷积层的感受野。红色的点表示滤波器的中心,而蓝色的点是在添加生成的偏移量后得到的。传统卷积运算的接受场均匀分布在二维网格上。另一方面,在可变形卷积的情况下,从图中可以明显看出,每个神经元根据其输入适应自己的感受野。当接近一个表格区域时(图3(a),图3(c))时,感受野扩大到覆盖了完整的表格,但在其他位置仍保持致密(图3(b),图3(d))。

可变形结构
论文配备了两种具有可变形卷积的目标检测模型。第一个模型是一个可变形faster R-CNN,它由一个可变形的base model组成,并用可变形的roi池化层代替传统的roi池化层。本文将该模型称为模型a。第二个模型是采用FPN框架的可变形特征金字塔网络(FPN)。在可变形的FPN中,再次使用可变形的base model,并将位置敏感的roi池化层替换为可变形的位置敏感的roi池化层
在所有的实验中,都使用了ResNet-101的base model。自可变形卷积是一个内存密集型操作由于生成的显式偏移的每个位置特性地图,论文只是取代了三个更高层次的层ResNet-101模型转换为可变形的对应层(可变形的感受野主要有助于层的层次结构)。这些层分别是res5a_branch2b、res5b_branch2b和res5c_branch2b。对于FPN的情况,作者另外将res3b3_branch2b层和res4b22_branch2b层替换为可变形的对应层,以帮助多尺度特征提取。
由于没有足够的数据来从头开始训练模型,所以作者利用迁移学习来训练模型。当使用可变形的ResNet-101时,作者将可变形的卷积层的偏移量初始化为零(零偏移量转化为固定的接受场,使其等同于传统的卷积操作)。由于网络在新数据集上进行了微调,偏移适应以应对表格结构的规模和转换。
值得注意的是,论文在目标检测模型中包含的唯一显著变化是使用可变形的基模型(可变形的ResNet-101)和使用可变形的roi池,而不是传统的roi池。这将传统的物体检测器转换为可变形的对应检测器。为了建立比较,论文还训练了一个具有传统卷积操作的ResNet-101模型,将这个非可变形的模型称为模型C。
超参数
为了训练模型A(可变形速度faster R-CNN),我们使用了三种不同的锚定比(0.5、1和2)和5种不同的锚定尺度(2、4、8、16和32)。为了训练模型B(可变形的FPN),我们使用了相同的锚定比(0.5、1和2),但只有一个锚定尺度(8),因为FPN另外配备了一个自上而下的路径用于多尺度检测。对于前250次迭代,优化模型的初始学习率为0.000125(多gpu训练时×NumGPUs)。然后使用速率为0.00125的学习速率(多gpu训练时×NumGPUs),在4、16和32个周期使用学习速率衰减步长。该模型经过了50次的优化。最大图像大小被限制为1280×800。超过这个尺寸的图像被调整大小,以保持纵横比不变。
实验
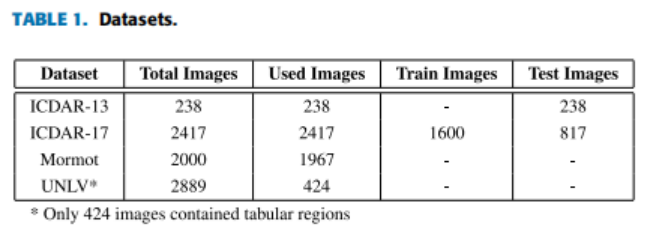
数据集:
实验使用了四个著名的公开的表检测数据集。数据集的细节,如表1。
ICDAR-13
ICDAR-2013是最著名的表检测和结构识别的数据集之一。数据集由PDF文件组成,论文将其转换为图像,以便在系统中使用。这是必需的,因为论文的系统只适用于图像,而不是大多数其他依赖于PDF文档中可用的元信息的方法。该数据集还包含了表结构识别任务的结构信息。该数据集总共包含238张图像。由于之前在这个数据集上的大部分工作都使用了0.5的IoU阈值来计算f1,论文也基于这个阈值评估模型。
ICDAR-17
POD最近发布了一个竞赛数据集(ICDAR-2017 POD),专注于从图像中检测表格、图形和数学方程的任务。该数据集总共由2417张图像组成。训练集由1600张图像组成,其余的817张图像用于测试。论文只评估了系统的表格检测任务,这是工作的重点。由于竞赛中所有提交的材料都是针对两个不同的IoU阈值0.6和0.8进行评估,论文报告了在这两个阈值上的表现。
MORMOT
由计算机科技研究所(北京大学)发布的Mormot是最大的公开可获得的表识别数据集。数据集中的图像总数为2000张。两组图像的正负图像样本的比例约为1:1。在数据集中有许多不正确的ground truth注释的实例。因此,使用实验数据集的清理版本。数据集的清理版本由实验中使用的1967张图像组成。
UNLV
UNLV数据集由各种文档组成,包括技术报告、商业信件、报纸和杂志等。该数据集总共包含2889个扫描文档,其中只有424个文档包含一个表格区域。在实验中,论文只使用了一个包含一个表格区域的图像。
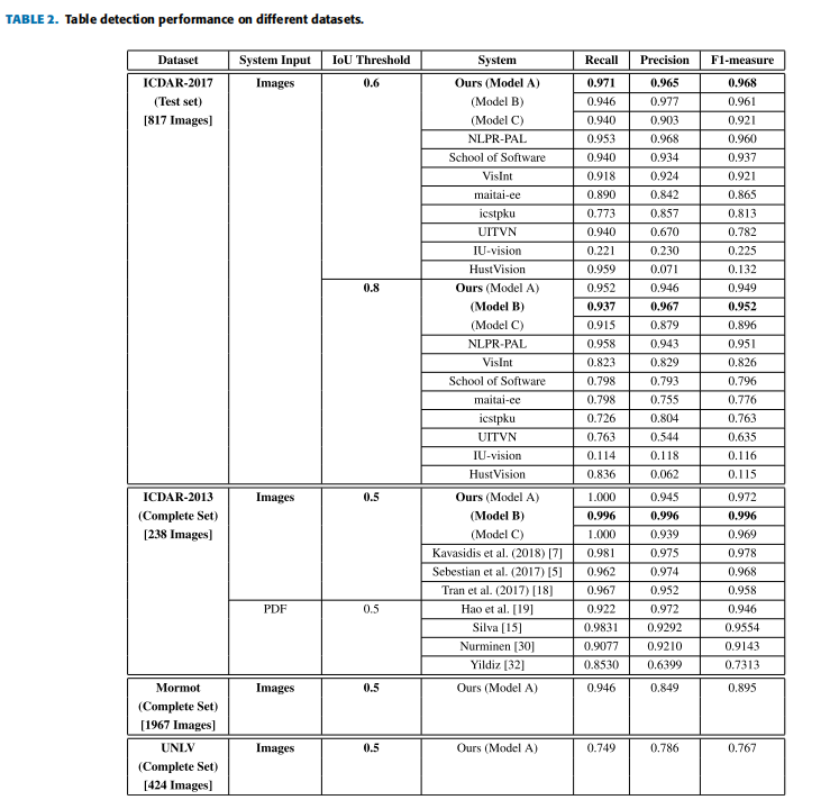
实验结果:表2比较了该方法与之前在ICDAR-2017 POD和ICDAR-2013数据集上的工作的性能。为了完成,还报告了UNLV和Mormot的结果,但这些数据集不是工作的重点。需要指出的是,依赖于PDF文档的系统不能与论文的系统进行直接比较,因为它们使用了PDF文件中包含的元数据,而论文的方法只依赖于原始图像,而没有额外的元数据。这使得这个问题更加具挑战性。
A.ICDAR-13
ICDAR-2013数据集由238张图像组成,包含156张表。实验使用数据集中的所有图像进行测试,而没有在训练中使用任何一幅图像。该系统只有一个表格区域没检测到,取得99.4%召回。类似地,系统只错误地将一个区域标记为属于表(false positive),导致精度为99.4%。图4给出了来自ICDAR-13数据集的正确和错误检测的代表性例子,包括 true positives, false positives, 和 false negatives。由于f-measure达到99.4%,在ICDAR- 2013数据集上全面优于之前的最先进的方法。
Schreiber等人使用了基于传统卷积运算的faster R-CNN的方法。由于它们的主干是基于ZFNet 和VGG-16 ,它们的模型没有直接的可比性。因此,实验添加了模型C具有相同的ResNet-101主干的实验结果。结果表明,可变形卷积的综合性能优于传统的卷积。

B.ICDAR-17 POD
ICDAR-2017 POD挑战包括817张图像,其中包含317张表格。所有参赛作品均在两个不同的IoU阈值0.6和0.8上进行评估,以计算相关指标。可变形faster R-CNN(模型A)在0.6时表现良好,达到96.8%,召回率为97.1%,准确率为96.5%。可变形的FPN(模型B)实现了0.8的阈值的最先进的结果,f-measure达到95.3%,召回率为93.1%,精度为97.7%。
图5显示了来自ICDAR- 17 POD数据集的正确和错误检测的代表性例子。根据所取得的结果,在IoU阈值分别为0.6和0.8时,本方法在表格检测任务上都优于所有其他ICDAR- 2017 POD挑战参与者。
对ICDAR-2017的错误结果进行分析发现,大部分错误与IoU有关。原因是不同的数据集组合在到表边界的距离方面有不同的注释。在极端情况下,有些情况下,表中的空单元格不被认为是表格区域的一部分。
实验再次将本方法的结果与传统的卷积对应的结果进行了比较。在这种情况下,可变形的卷积也优于传统的卷积。

C.MORMOT
MORMOT数据集由1967张图像组成,共包含1348张表。除了Mormot之外,在其他三个数据集中训练的可变形faster R-CNN能够正确地检测到1275个表实例。该系统还产生了226个false positives和73个false negatives,导致召回率为94.6%,准确率为84.9%。这导致了最终的f-measure为89.5%。图6给出了来自Mormot数据集的正确和错误检测的代表性例子,包括true positives, false positives, 和 false negatives。

D.UNLV
UNLV数据集也同样由424张图像组成,总共包含558张表。采用相同的留一方案训练的可变形快速RCNN能够正确检测418个表实例。该系统还产生了114个false positives和140个false negatives,导致召回率为74.9%,准确率为78.6%,最终的f-measure为76.7%。图7显示了UNLV正确分类的表格区域,而图8显示了不正确分类的表格区域。


结论:论文提出了一种基于region-based的可变形卷积神经网络的端到端表格检测方法。从对所提出方法的广泛评估中可以明显看出,为自然场景中目标检测而开发的深度架构辅以可变形特性可以全面优于非变形的方法。
Semi-Supervised Deformable DETR
2023年的论文《Towards End-to-End Semi-Supervised Table Detection with Deformable Transformer》本文提出了一种新的端到端半监督表格检测方法,利用可变形transformer来检测表格对象。本方法在PubLayNet、DocBank、ICADR-19和TableBank数据集上评估了我们的半监督方法,它比以往的方法取得了更好的性能。
算法原理:Deformable DETR
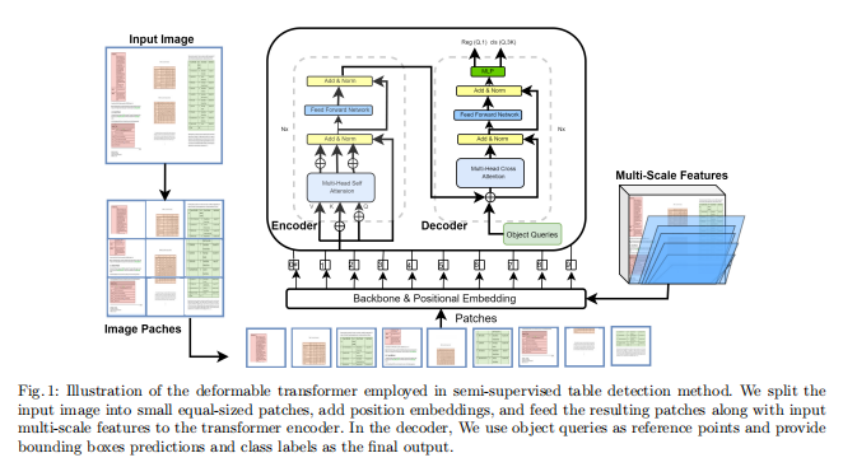
可变形的DETR 包含一个Transformer encoder-decoder网络,它将目标检测视为一个可设置的预测任务。它使用了Hungarian损失,并通过双向图匹配避免了对ground truth边界框的重叠预测。它消除了对人工参与的元素的需要,如锚点和后处理阶段,如在基于cnn的对象检测器中使用的非最大抑制(NMS)。可变形的DETR是DETR体系结构的一个扩展,它解决了DETR的一些限制,如训练收敛速度慢和在小对象上的性能差。可变形的DETR在体系结构中引入了可变形的卷积,这允许更灵活的对象形状建模和更好地处理不同尺度的对象。这可以提高性能,特别是在小物体上,并在训练过程中更快地收敛。图1显示了可变形transformer所有模块,包括多尺度特征和编解码器网络。

Transformer Decoder
解码器网络以编码器特征的输出和N个对象query作为输入。它包含两种注意类型和self-attention和cross-attention。self-attention模块查找对象query之间的连接。这里的key和query矩阵都包含对象query。cross-attention模块使用对象query从输入特征图中提取特征。这里的key矩阵包含编码器模块提供的特征映射,query矩阵是作为解码器输入的对象query。在注意模块之后,添加前馈网络(FFN)和线性投影层作为预测头。线性投影层预测类标签,而FFN提供最终的边界框坐标值。
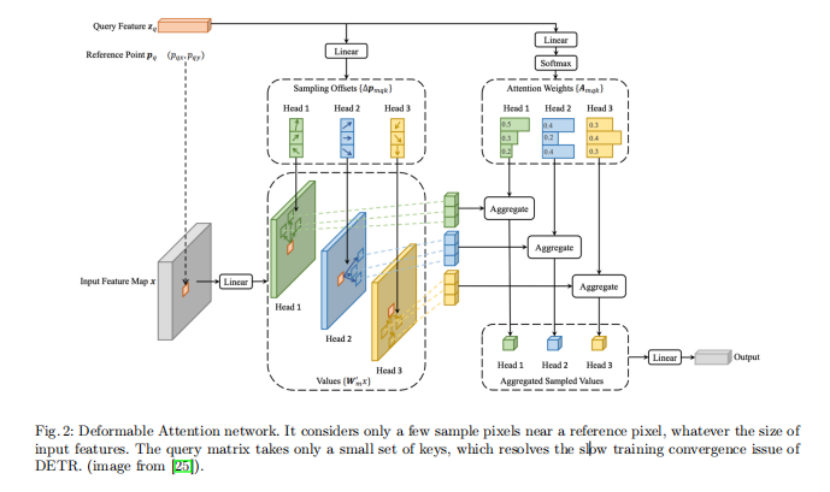
Deformable Attention Module
DETR网络中的Attention模块考虑了输入特征图的所有空间位置,这使得训练的收敛速度较慢。然而,一个可变形的DETR可以利用基于可变形卷积的Attention网络和多尺度输入特征来解决这一问题。它只考虑一个参考像素附近的几个样本像素,无论输入特征的大小如何,如图2所示。Query矩阵只需要一小部分key,解决了DETR训练收敛速度慢的问题。
Semi-Supervised Deformable DETR
半监督可变形DETR是一种统一的学习方法,它使用完全标记和未标记的数据来进行目标检测。它包含两个模块,一个是学生模块和一个是教师模块。训练数据有两种数据类型,标签数据和未标记数据。学生模块将标记和未标记图像作为输入,其中对未标记数据应用强增强,而对标签数据应用(强增强和弱增强)。学生模块通过伪框使用已标记数据和未标记数据的检测损失进行训练。未标记的数据包含两组用于提供类标签的伪框及其边界框。教师模块在应用弱增强后,只将未标记的图像作为输入。图3是pipeline的摘要。教师模块将预测结果提供给伪标记框架,得到伪标签。然后,学生模块使用这些伪标签进行监督训练。这里,教师模块使用对未标记数据的弱增强来生成更精确的伪标签。通过对未标记数据的强增强,使学生模块具有更具挑战性的学习。学生模块还以一小部分具有强增强和弱增强的标记图像作为输入。对学生模块sm进行了优化,总损失如下:
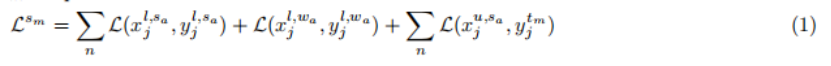


训期间,学生模块使用指数移动平均(EMA)策略不断更新教师模块。将概率分布视为伪标签,伪标签生成是简单的。相比之下,目标检测任务更加复杂,因为一个图像可能包含许多对象,而注释包含对象位置和类标签。基于cnn的对象检测器使用锚点作为对象建议,并通过非最大抑制(NMS)等后处理步骤去除冗余的方框。

下篇继续介绍~

合合信息是一家人工智能及大数据科技企业,基于自主研发的领先的智能文字识别及商业大数据核心技术,为全球C端用户和多元行业B端客户提供数字化、智能化的产品及服务。
| 联系人: | 透明七彩巨人 |
|---|---|
| Email: | weok168@gmail.com |
