常用的表格检测识别方法——表格结构识别方法 (下)
- 2023-06-25 18:05:00
- 刘大牛 转自文章
- 736
常用的表格检测识别方法——表格结构识别方法(下)
3.2表格结构识别方法
表格结构识别是表格区域检测之后的任务,其目标是识别出表格的布局结构、层次结构等,将表格视觉信息转换成可重建表格的结构描述信息。这些表格结构描述信息包括:单元格的具体位置、单元格之间的关系、单元格的行列位置等。在当前的研究中,表格结构信息主要包括以下两类描述形式:1)单元格的列表(包含每个单元格的位置、单元格 的行列信息、单元格的内容);2)HTML代码或Latex代码(包含单元格的位置信息,有些也会包含单元格的内容)。
与表格区域检测任务类似,在早期的表格结构识别方法中,研究者们通常会根据数据集特点,设计启发式算法或者使用机器学习方法来完成表格结构识别任务。
Itonori(1993)根据表格中单元格的二维布局的 规律性,使用连通体分析抽取其中的文本块,然后 对每个文本块进行扩展对齐形成单元格,从而得到 每个单元格的物理坐标和行列位置。Rahgozar等人 (1994)则根据行列来进行表格结构的识别,其先 识别出图片中的文本块,然后按照文本块的位置以及两个单元格中间的空白区域做行的聚类和列的聚类,之后通过行和列的交叉得到每个单元格的位 置和表格的结构。
Hirayama等人(1995)则从表格线出发,通过平行、垂直等几何分析得到表格的行和列,并使用动态规划匹配的方法对各个内容块进 行逻辑关系识别,来恢复表格的结构。Zuyev(1997) 使用视觉特征进行表格的识别,使用行线和列线以及空白区域进行单元格分割。该算法已经应用到FineReader OCR产品之中。Kieninger等人(1998) 提出了T-Recs(Table RECognition System)系统,以 词语区域的框作为输入,并通过聚类和列分解等启 发式方法,输出各个文本框对应的信息,恢复表格 的结构。随后,其又在此基础上提出了T-Recs++系 统(Kieninger等,2001),进一步提升了识别效果。Amano等人(2001)创新性地引入了文本的语义信息,首先将文档分解为一组框,并将它们半自动地 分为四种类型:空白、插入、指示和解释。然后根据 文档结构语法中定义的语义和几何知识,分析表示 框与其关联条目之间的框关系。
Wang等人(2004) 将表格结构定义为一棵树,提出了一种基于优化方 法设计的表结构理解算法。该算法通过对训练集中 的几何分布进行学习来优化参数,得到表格的结构。 同样使用树结构定义表格结构的还有Ishitani等人 (2005),其使用了DOM(Document Object Model) 树来表示表格,从表格的输入图像中提取单元格特 征。然后对每个单元格进行分类,识别出不规则的 表格,并对其进行修改以形成规则的单元格排布。Hassan(2007)、Shigarov(2016)等人则以PDF文 档为表格识别的载体,从PDF文档中反解出表格视 觉信息。后者还提出了一种可配置的启发式方法框架。
国内的表格结构识别研究起步较晚,因此传统的启发式方法和机器学习方法较少。
在早期,Liu等 人(1995)提出了表格框线模板方法,使用表格的 框架线构成框架模板,可以从拓扑上或几何上反映 表格的结构。然后提出相应的项遍历算法来定位和 标记表格中的项。之后Li等人(2012)使用OCR引擎抽取表单中的文本内容和文本位置,使用关键词 来定位表头,然后将表头信息和表的投影信息结合 起来,得到列分隔符和行分隔符来得到表格结构。
总体来说,表格结构识别的传统方法可以归纳为以下四种:基于行和列的分割与后处理,基于文本的检测、扩展与后处理,基于文本块的分类和后处理,以及几类方法的融合。
随着神经网络的兴起,研究人员开始将它们应用于文档布局分析任务中。后来,随着更复杂的架构的发展,更多的工作被放到表列和整体结构识别中。
A Zucker提出了一种有效的方法CluSTi,是一种用于识别发票扫描图像中的表格结构的聚类方法。CluSTi有三个贡献。首先,它使用了一种聚类方法来消除表格图片中的高噪声。其次,它使用最先进的文本识别技术来提取所有的文本框。最后,CluSTi使用具有最优参数的水平和垂直聚类技术将文本框组织成正确的行和列。Z Zhang提出的分割、嵌入和合并(SEM)是一个准确的表结构识别器。M Namysl提出了一种通用的、模块化的表提取方法。
E Koci 提出了一种新的方法来识别电子表格中的表格,并在确定每个单元格的布局角色后构建布局区域。他们使用图形模型表示这些区域之间的空间相互关系。在此基础上,他们提出了删除和填充算法(RAC),这是一种基于一组精心选择的标准的表识别算法。
SA Siddiqui利用可变形卷积网络的潜力,提出了一种独特的方法来分析文档图片中的表格模式。P Riba提出了一种基于图的识别文档图片中的表格结构的技术。该方法也使用位置、上下文和内容类型,而不是原始内容(可识别的文本),因此它只是一种结构性感知技术,不依赖于语言或文本阅读的质量。E Koci使用基于遗传的技术进行图划分,以识别与电子表中的表格匹配的图的部分。
SA Siddiqui将结构识别问题描述为语义分割问题。为了分割行和列,作者采用了完全卷积网络。假设表结构的一致性的情况下,该方法引入了预测拼接方法,降低了表格结构识别的复杂性。作者从ImageNet导入预先训练的模型,并使用FCN编码器和解码器的结构模型。当给定图像时,模型创建与原始输入图像大小相同的特征。
SA Khan提出了一个鲁棒的基于深度学习的解决方案,用于从文档图片中已识别的表格中提取行和列。表格图片经过预处理,然后使用门控递归单元(GRU)和具有softmax激活的全连接层发送到双向递归神经网络。SF Rashid提供了一种新的基于学习的方法来识别不同文档图片中的表格内容。SR Qasim提出了一种基于图网络的表识别架构,作为典型神经网络的替代方案。S Raja提出了一种识别表格结构的方法,该方法结合了单元格检测和交互模块来定位单元格,并根据行和列预测它们与其他检测到的单元格的关系。此外,增加了结构限制的损失功能的单元格识别作为额外的差异组件。Y Deng 测试了现有的端到端表识别的问题,他还强调了在这一领域需要一个更大的数据集。
Y Zou的另一项研究呼吁开发一种利用全卷积网络的基于图像的表格结构识别技术。所示的工作将表格的行、列和单元格划分。所有表格组件的估计边界都通过连接组件分析进行了增强。根据行和列分隔符的位置,然后为每个单元格分配行和列号。此外,还利用特殊的算法优化单元格边界。
为了识别表中的行和列,KA Hashmi [118]提出了一种表结构识别的引导技术。根据本研究,通过使用锚点优化方法,可以更好地实现行和列的定位。在他们提出的工作中,使用掩模R-CNN和优化的锚点来检测行和列的边界。
另一项分割表格结构的努力是由W Xue撰写的ReS2TIM论文,它提出了从表格中对句法结构的重建。回归每个单元格的坐标是这个模型的主要目标。最初使用该新技术构建了一个可以识别表格中每个单元格的邻居的网络。本研究给出了一个基于距离的加权系统,这将有助于网络克服与训练相关的类不平衡问题。
C Tensmeyer提出了SPLERGE(Split and Merge),另一种使用扩展卷积的方法。他们的策略需要使用两种不同的深度学习模型,第一个模型建立了表的网格状布局,第二个模型决定了是否可能在许多行或列上进行进一步的单元格跨度。
Nassar为表格结构提供了一个新的识别模型。在两个重要方面增强了PubTabNet端到端深度学习模型中最新的encoder-dual-decoder。首先,作者提供了一种全新的表格单元目标检测解码器。这使得它们可以轻松地访问编程pdf中的表格单元格的内容,而不必训练任何专有的OCR解码器。作者称,这种体系结构的改进使表格内容的提取更加精确,并使它们能够使用非英语表。第二,基于transformer的解码器取代了LSTM解码器。
S Raja提出了一种新的基于目标检测的深度模型,它被定制用于快速优化并捕获表格内单元格的自然对齐。即使使用精确的单元格检测,密集的表格识别也可能仍然存在问题,因为多行/列跨行单元格使得捕获远程行/列关系变得困难。因此,作者也寻求通过确定一个独特的直线的基于图的公式来增强结构识别。作者从语义的角度强调了表格中空单元格的相关性。作者建议修改一个很受欢迎的评估标准,以考虑到这些单元格。为了促进这个问题的新观点,然后提供一个中等大的进行了人类认知注释后的评估数据集。
X Shen提出了两个模块,分别称为行聚合(RA)和列聚合(CA)。首先,作者应用了特征切片和平铺,对行和列进行粗略的预测,并解决高容错性的问题。其次,计算信道的attention map,进一步获得行和列信息。为了完成行分割和列分割,作者利用RA和CA构建了一个语义分割网络,称为行和列聚合网络(RCANet)。
C Ma提出了一种识别表格的结构并从各种不同的文档图片中检测其边界的新方法。作者建议使用CornerNet作为一种新的区域候选网络,为fasterR-CNN生成更高质量的候选表格,这大大提高了更快的R-CNN对表格识别的定位精度。该方法只利用最小的ResNet-18骨干网络。此外,作者提出了一种全新的split-and-merge方法来识别表格结构。该方法利用一种新的spatial CNN分割线预测模块将每个检测表格划分为一个单元网格,然后使用一个GridCNN单元合并模块来恢复生成单元格。它们的表格结构识别器可以准确地识别具有显著空白区域的表格和几何变形(甚至是弯曲的)表格,因为spatial CNN模块可以有效地向整个表图片传输上下文信息。B Xiao假设一个复杂的表格结构可以用一个图来表示,其中顶点和边代表单个单元格以及它们之间的连接。然后,作者设计了一个conditional attention网络,并将表格结构识别问题描述为一个单元格关联分类问题(CATT-Net)。
Jain建议训练一个深度网络来识别表格图片中包含的各种字符对之间的空间关系,以破译表格的结构。作者提供了一个名为TSR-DSAW的端到端pipeline:TSR,通过深度空间的字符联系,它以像HTML这样的结构化格式生成表格图片的数字表示。该技术首先利用文本检测网络,如CRAFT,来识别输入表图片中的每个字符。接下来,使用动态规划,创建字符配对。这些字符配对在每个单独的图像中加下划线,然后交给DenseNet-121分类器,该分类器被训练来识别同行、同列、同单元格或无单元格等空间相关性。最后,作者将后处理应用于分类器的输出,以生成HTML表格结构。
H Li将这个问题表述为一个单元格关系提取的挑战,并提供了T2,一种前沿的两阶段方法,成功地从数字保存的文本中提取表格结构。T2提供了一个广泛的概念,即基本连接,准确地代表了单元格之间的直接关系。为了找到复杂的表格结构,它还构建了一个对齐图,并使用了一个消息传递网络。
实际场景应用中的表格结构识别,不仅要同时完成表格检测和结构识别,还要对每个单元格的文本进行识别和信息抽取,其流程比以上的研究领域都更为复杂。
3.2.1先进的表格结构识别模型
SPLERGE
ICDAR 2019的表格结构识别最佳论文《Deep Splitting and Merging for Table Structure Decomposition》提出了一对新的深度学习模型SPLERGE(分割和合并模型),它们给定一个输入图像,1)预测基本的表格网格模式,2)预测应该合并哪些网格元素来恢复跨越多行或列的单元格。该方法提出投影池作为分割模型的一个新组成部分,而网格池作为合并模型的一个新组成部分。虽然大多数完全卷积网络依赖于局部证据,但这些独特的池化区域允许模型利用全局表格结构。该方法在PDF文档的公共ICDAR 2013表格竞赛数据集上取得了最先进的性能。在作者用来训练模型的一个更大的私有数据集上,性能明显优于一个此前最先进的深度模型和一个主要的商业软件系统。
SPLERGE算法原理:
论文提出的表格结构提取方法是SPLERGE,它由两个深度学习模型组成,它们按顺序执行分割和合并操作(见图1)。分割模型接受一个裁剪良好的表格的输入图像,并以跨越整个图像的行和列分隔符的形式生成表格的网格结构。由于某些表包含生成单元格,因此作者将合并模型应用于拆分模型的网格输出,以将相邻的网格元素合并在一起,以恢复生成单元格。

分割模型(Split Model)
分割模型以任何维数H×W的图像作为输入,并产生两个一维输出信号:r∈[0,1]H和c∈[0,1]W。输出信号r和c表示像素中的每一行(列)是逻辑表行(列)分隔符区域的一部分的概率。
分割模型由3个子网络组成:
1)共享全卷积网络(SFCN)
2)行投影网络(RPN)
3)列投影网络(CPN)
SFCN计算RPN和CPN都在使用的局部图像特征。然后,RPN和CPN将这些局部特征进行进一步处理,以预测行和列分隔符(分别为r和c)。
SFCN由3个卷积层和7x7核的卷积层组成,最后一层进行膨胀系数为2的膨胀卷积。每一层产生18个特征映射,并使用ReLU激活函数。
膨胀卷积,比如池化,增加了网络的感受野,但与池化不同的是,它们保留了输入的空间分辨率。保留输入的空间分辨率在表结构提取中很重要,因为许多列和行分隔器只有几个像素宽。在[6]中,当调整初始输入的大小以使分隔符区域更大时,获得了更好的结果。有一个大的接受域也是至关重要的,因为确定行和列分隔符的位置可能需要全局上下文。例如,始终左对到相同位置的文本表示列分隔符。
SFCN的输出被作为RPN和CPN的输入。RPN的输出为r,即每一行像素是行分隔符区域的一部分的概率。同样,CPN的输出为c。因为RPN和CPN具有相同的结构,除了投影和池化操作是在像素的行还是列上,所以只集中讨论RPN。
尽管可以使用任意数量的块,但本方法中的RPN是由5个链接在一起的块组成的。根据经验,使用超过5个块并没有改善结果,同时作者使用了类似的过程来确定其他特定的架构选择。为了简化讨论和说明,作者在实验中使用了实际的超参数值,但也可以使用其他合理的值。在一个合理的范围内改变超参数似乎并没有对非正式实验的结果产生显著的影响。图2显示了由单个块所执行的操作。首先,输入(并行)输入3个卷积层,其膨胀因子为2/3/4,每个层产生6个特征映射。将每个展开卷积的输出连接起来,得到18个特征映射。使用多种扩张因子可以使RPN学习多尺度特征,并增加其感受野,同时仍然采集更多的局部信息。
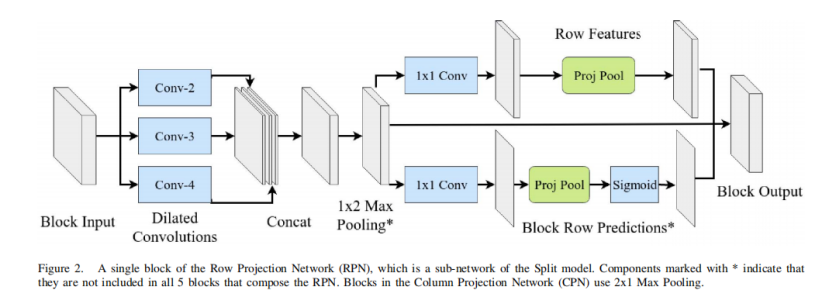
接下来,RPN执行1x2最大池化(CPN执行2x1最大池化)。这减小了特征图的宽度,但保持了高度,因此输出信号r的大小为h。只有前三个块执行最大池,以确保宽度不会被下采样。
然后,RPN通过1x1的卷积操作,然后进行投影池化(图3),计算行特征(图2的顶部分支)。投影池化的灵感来自于经典布局分析中用于寻找空白间隙的投影轮廓操作。作者使用投影池化保持输入的空间大小(而不是像投影剖面图中那样折叠到一维),并简单地用它的行平均值替换输入中的每个值。具体来说,
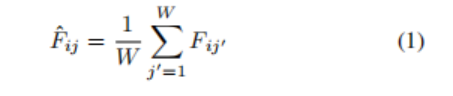
其中i,j分别是在特征映射F中的行列索引,1≤j≤W。作者称 hat{F}为F的行投影池化,并在每个特征映射上独立应用此操作,这是典型的池化操作。以这种方式池化允许信息在图像的整个宽度上传播,这可能超过1000个像素。这些行特征被连接到最大池化操作的输出中,这样每个像素都具有局部和行全局特征。CPN执行列投影池,类似地是,
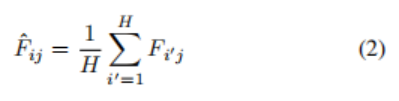
图2的底部分支显示了块如何产生行预测,尽管不是每个块都这样做。一个1x1的卷积产生一个单一的输出映射,作者在其上执行投影池。然后作者应用一个sigmoid函数来产生概率。由于每一行像素都包含一个唯一的概率,作者可以取一个垂直切片得到一个一维概率信号 r^n,其中n表示块索引。为了使中间预测 r^n可用于第n + 1块,作者还将2D中的概率连接到块的输出中。
在作者的实现中,只有最后3个块产生输出,即r3、r4、r5。在训练过程中,作者对所有三个预测都应用了一个损失,但在训练后,作者只使用最后一个预测r5来进行推理。这种迭代预测过程允许模型做出预测,然后优化该预测。这些技术已经成功地应用于以往的自然场景中的结构化关键点检测任务。

1) 训练:
SFCN、RPN和CPN子网络在150 DPI的表格图像以典型的监督方式进行联合训练。作者假设图像被裁剪为只包含表单元格,并排除不在单元格区域内的表格标题、标题和脚注。

每个表都有注释的GT一维信号 r^*和 c^*。GT的设计是为了最大化分隔区域的大小,而不相交于任何非跨行单元的内容,如图4所示。这与传统的单元格分隔符的概念相反,对于许多表来说,单元格分隔器是只有几个像素厚的细线。预测小区域比预测大区域更困难,而且在无线表格的情况下,单元格分隔符的确切位置定义不明确。GT分隔符区域可能与跨越多行或列的单元格内容相交。分割模型的目标是恢复表格的基本网格,并且生成单元格由合并模型来处理。
损失函数是块预测和GT信号之间的平均元素二值化交叉熵:
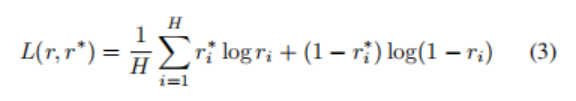
为了防止过拟合,作者修改方程3,在 lvert r^*_i-r_i lvert <0.1时,将损失收缩为0。总损失是单个输出损失的加权和:
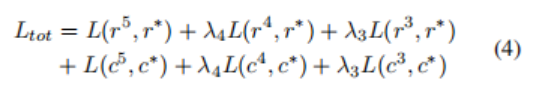
其中,作者设置了 lambda _4= 0.25和 lambda _3= 0.1。作者使用ADAM优化器随机初始化训练模型,进行大约 10^6次权重更新。作者使用批处理大小为1,因为表格图像有不同的空间大小。作者使用0.00075的初始学习率,每进行80K更新就会衰减0.75倍。
2) 推理:
一旦预测了r,就需要推断行分隔符出现在哪个像素位置。为简单起见,讨论集中在r上,但同样的程序也适用于c,以获得列分隔符。为此,作者通过在r上执行图形切割分割,将图像分割为行和行分隔符区域。然后,作者选择与每个推断的分隔符区域的中点对应的行像素位置。
为了创建分割r的图,作者有H个节点排列在一个线性链中,其中每个节点都连接到它的两个邻居(除了两端的两个节点)。邻域边权值均匀设置为 lambda _{gc}= 0.75。节点i连接到边权值为r i的源节点和边权值为1− r_i的接收节点。
合并模型(Merge Model)
合并模型使用输入图像和分割模型的输出来预测需要合并哪些网格元素,以恢复跨多行或列的单元格。输入张量是表格图像,输出行/列概率(r、c),推理的行/列区域和预测的网格结构的连接。预测的概率r和c通过叠加(即,[r,r,……,r]))转换为二维图像。推理出的行/列区域被呈现为二进制掩模(类似于图4中的红色区域)。预测的网格结构被渲染为一个二进制掩模,其中每行和列分隔符区域的中点被渲染为一条7像素宽的线。此外,网格结构还用于确定模型的池化区域。
如果网格结构由M行和N列组成,则模型输出两个矩阵:
1) D - probs。上下合并(大小为(M−1)× N)
2) R - probs。左右合并(大小为M ×(N−1))
D_{ij}是单元格(i,j)与单元格(i+1,j)合并的概率, R_{ij}是单元格(i,j)和(i,j+1)合并的概率。D的大小不是M×N,因为在任何一列中只有M−1对上下合并。
在作者的公式中,所有这些概率都是独立的,即单个网格单元可以在多个方向上合并。合并模型的体系结构类似于分割模型。有一组4个共享的卷积层(没有膨胀),其中2x2的平均池化发生在第2层和第4层之后。然后,该模型有4个分支,每个分支预测一个单元格在特定方向上合并的M×N概率矩阵,即上、下、左或右。将这些矩阵称为u,d,l,r。而作者的独立性假设表明作者在方程式中将两个个体的概率相乘。在公式5,6中,当两个概率都接近于0时,这将引入优化困难,所以作者计算D和R为
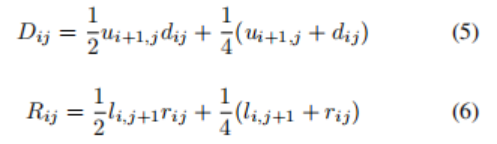
直观地说,作者只预测,在单个分支输出之间存在一致性的情况下,应该将一对单元格合并。
每个分支由3个块组成,与图2中所示的分割模型块相似。不同之处在于,平行卷积层使用了1/2/3的膨胀因子,没有执行最大池化,投影池化被网格池化取代(图5)。在网格池化中,每个像素位置替换其网格元素内的所有像素的平均值:
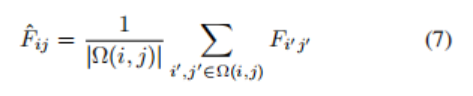
其中,Ω(i,j)是与(i,j)共享相同网格元素的所有像素的坐标集。在网格池之后,同一网格元素内的所有像素共享相同的值,这允许信息在每个单元格内传播。随后的卷积允许信息在相邻的单元格之间传播。为了生成给定分支的u,d,l或r矩阵,作者将每个网格元素中预测的周围像素概率平均,并将它们排列在一个M×N矩阵中。与分割模型一样,合并模型也执行迭代输出优化,其中块2和块3产生输出预测。
1) 训练:
因为分裂和合并模型是打算按顺序使用的,所以作者使用分裂模型产生的网格结构来训练合并模型。构造GT D和R矩阵(见图6),作者
1) 在表格迭代所有生成的单元格
2) 确定网格元素相交的GT边界框
3) 对适当的方向,设置每个单元合并的概率为1

在Split模型中,每个输出的损失函数是平均(裁剪)元素级的二进制交叉熵(公式4)。总损失是
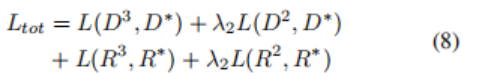
因为生成单元格只出现在用于训练模型的私有数据集中的15%的表格中,所以作者对这个数据集进行子采样,以便合并模型的50%的训练集至少有一对需要合并的单元格。训练超参数与分割模型相似。
以0.5的概率对D和R进行阈值计算,并合并指示的单元格。网络预测没有对生成的合并只产生矩形单元格的约束,因此在后处理中添加了额外的合并,以确保生成的表结构只有矩形单元格。例如,将3个网格元素合并在一起形成一个L形单元格,然后将与第4个元素合并,以创建一个跨越2行2列的单元格。
实验:
ICDAR2013:
实验在ICDAR 2013数据集上的结果来自于在私有数据集上训练的模型。作者试图验证改进的性能来自于一个更好的深度模型,而不仅仅是来自一个更大的训练集。作者通过重新实现DeepDeSRT模型,并在与本文提出的模型相同的数据上进行训练来做到这一点。
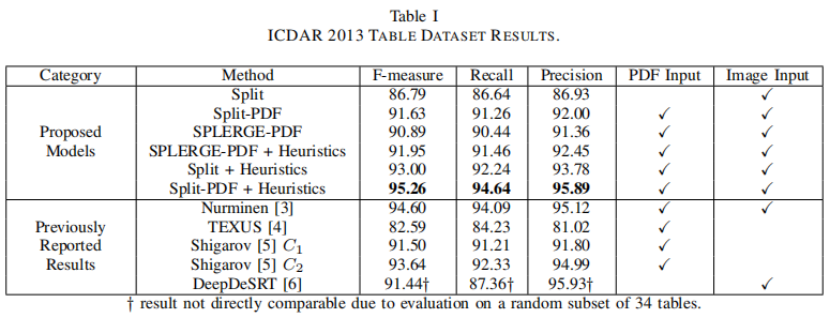
表一显示了模型在ICDAR 2013数据集(任务2)上的结果。带有-PDF后缀的方法表明使用了额外的PDF渲染的输入通道。该数据集的评估度量是对检测到的邻接关系的f-score。粗略地说,这测量的是正确检测到的相邻单元格对的百分比,正确检测表示两个单元格都被正确地分割并被识别为相邻单元格。
对于这个数据集,合并模型未能为分割模型的输出提供足够的后处理。在执行预测的合并后,后处理结合了额外的单元格,以防止单元格在最终输出中形成L形。在ICDAR 2013数据集中的几个大标题区域中,由于一些错误的成对合并预测产生了L形,大量的单个单元群被合并为单个单元群。作者没有进一步细化启发式方法以防止L形图形的出现,而是实现了一些简单的启发式方法,可以替代合并模型。 这些启发式包括
•合并预测的分隔符通过文本的单元格。
•当绝大多数成对的单元格(在第3行之后)都为空白或每对只有一个单元格是非空白时,合并相邻的列。这将将一个内容列与(大部分)空白列合并。
•在第一行(可能是标题行)中,将非空白单元格与相邻的空白单元格合并。
•在垂直对齐的文本之间具有连续的空白间隙的分割列。
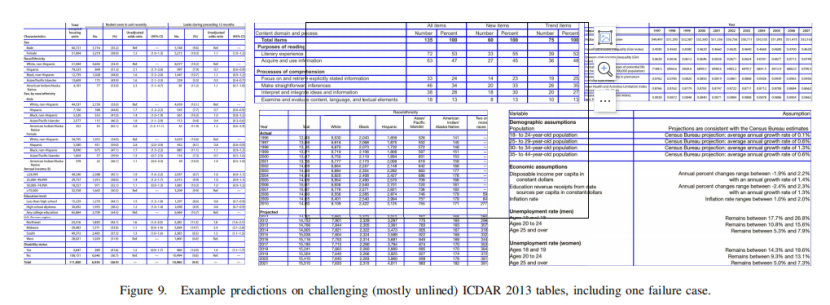
图8中显示了一些由启发式方法固定的示例表。虽然Split模型在识别表格网格方面表现良好,但它有时会犯一些很容易纠正的错误,并且不能自己处理生成单元格。当结合简单的启发式方法来处理这些情况时,它实现了95.26%的f-measure,而之前的最佳结果为94.60%。Merge模型未能从私有集合推广到ICDAR 2013数据集,但如表二所示,它确实提高了私有集合的性能。图9显示了一些通过Split-PDF +启发式对无线表的预测示例,这些预测比有线表更难识别。
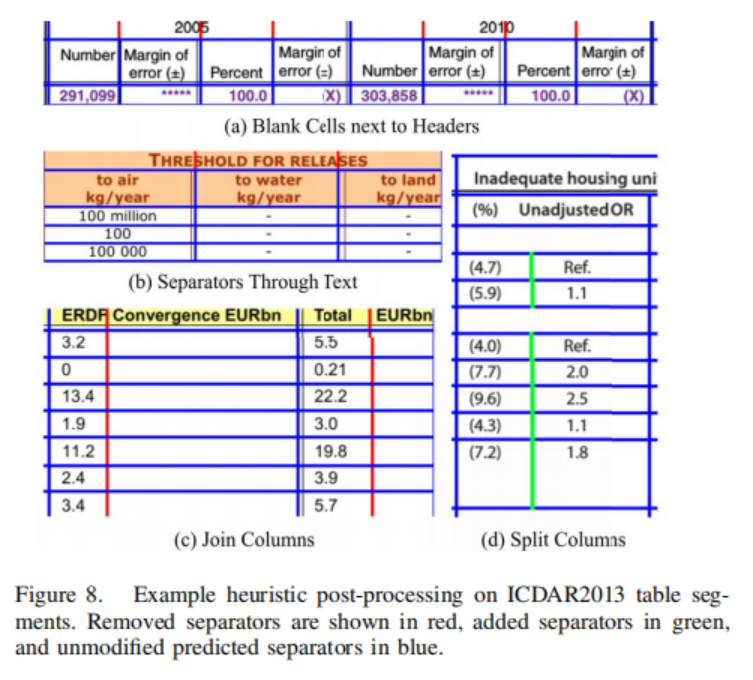
与PDF信息(文本、路径、图像通道)作为分割模型的输入和不是时,有很大的性能差异。由于在私有集合上的差异不那么大(表II),作者得出结论,PDF输入通道的有效性取决于数据集。ICDAR表主要是排列的,有更大的标题,与训练数据集相比,可能有明显的视觉外观。因此,额外的PDF信息可能在不熟悉的领域中更有帮助,因为文本和路径元素是显式的输入,而不需要由模型直观地推断。
作者复现了DeepDeSRT表结构模型,并在与作者提出的模型相同的私有数据上对其进行了训练。然而,即使作者探索了各种后处理阈值和训练超参数,作者也无法获得合理的性能。在DeepDeSRT,他们报告的FM为91.44%,超过了34个表的随机子集,因此不能进行直接比较。作者认为,这一差距表明,作者不能忠实地重现他们的模型,以进行公平的比较。然而,作者使用的训练集非常不同,并且在私有集合和ICDAR 2013数据集之间存在显著差异。这些原因可以解释性能差距,但差距足够大,以至于作者不确定作者的实现是否是Deep DeSRT的忠实复现,因此作者省略了精确的性能数字,以避免直接比较。
私有数据集:
在这个数据集上,作者使用精度和对正确检测到的细胞的召回率来评估方法。作者还报告了具有完美精确度和召回率的表的百分率。如果一个预测的边界框(BB)完全只包含一个GT单元格内容BB,那么它将是一个正确的预测。特别是,与多个GT BB相交或不完全包含任何GT BB的预测BB被标记为false positive。不匹配的GT BB被标记为false negative。因为空白单元格没有被手动注释,所以作者排除了不与任何GT BB相交的预测BB。这样,如果方法正确地预测了未标记的空白单元格,那么它们就不会受到惩罚。
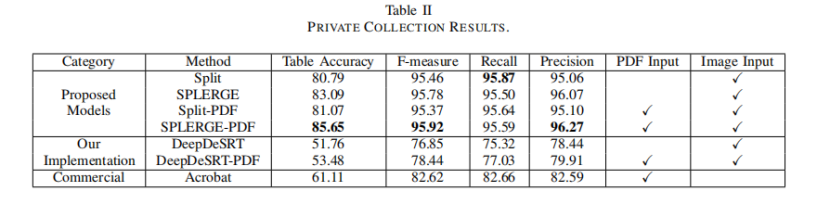
表二显示了测试集上5000个表格的结果。根据每个表计算报告的准确率和召回率,然后取平均值。作者无法找到之前工作的任何官方实现,所以为了进行比较,作者使用了商业软件系统Acrobat Pro DC和作者复现的DeepDeSRT模型。
作者提出的模型的所有变体在所有指标上都显著优于两个baseline。作者还看到,因为使用分割模型不能单独处理具有跨行单元格的表,合并模型显著提高了表格的准确性。对于需要合并的表,每个表需要合并的平均数量比ICDAR 2013要少得多,从而导致更少的L形预测。作者还观察到,使用PDF信息作为输入确实带来了改善,但比ICDAR 2013的数据更轻微。这可能反映了这样一个事实,即ICDAR 2013和私有集合之间的域差异在渲染的PDF中更为明显,但当只检查文本或路径图像通道时,差异就减少了。这表明这种方法可能是有效的。

结论:
论文提出了一种新的表格结构提取方法。它由一对深度学习模型组成,这些模型一起将一个表格图像分割成基本的单元格网格,然后将单元格合并在一起,以恢复跨越多行和多列的单元格。该模型的关键见解是在表格图像的大区域上汇集信息,如像素的整个行/列或先前预测的单元格区域。当在ICDAR 2013表格竞赛数据集上评估分割模型时,实现了最先进的性能。
实验还证明了PDF信息,如页面元素是否是文本/路径/图像,可以编码为深度网络的输入,并提高性能。但是,如果这些信息不可用(例如,扫描的文档),该模型只能使用灰度图像作为输入。最后,证明了合并模型对从web中提取的表格私有数据集是有效的。
TSRFormer
2022年微软研究院的论文《TSRFormer: Table Structure Recognition with Transformers》提出了一种新的表格结构识别(TSR)方法,称为TSRFormer,以从各种表格图像中稳健地识别具有几何畸变的复杂表格的结构。与以往的方法不同,该方法将表格分割线预测定义为线回归问题而不是图像分割问题,并提出了一种新的基于两阶段DETR的分割预测方法,称为 Separator REgression TRansformer(SepRETR),以直接预测表图像中的分割线。为了使两阶段DETR框架有效地适合于分割线预测任务,作者提出了两个改进:1)先验增强匹配策略来解决DETR的慢收敛问题;2)一种新的交叉注意模块直接从高分辨率卷积特征图中采样特征,从而在较低计算成本的情况下实现较高的定位精度。
TSRFormer算法原理:
如图1所示,TSRFrorter包含两个关键组件:1)基于SepRETR的分割模块,用于预测每个输入表图像中的所有行和列分离线;2)基于关系网络的单元合并模块来恢复生成单元。这两个模块被连接到一个由ResNet-FPN主干生成的共享卷积特征图P2上
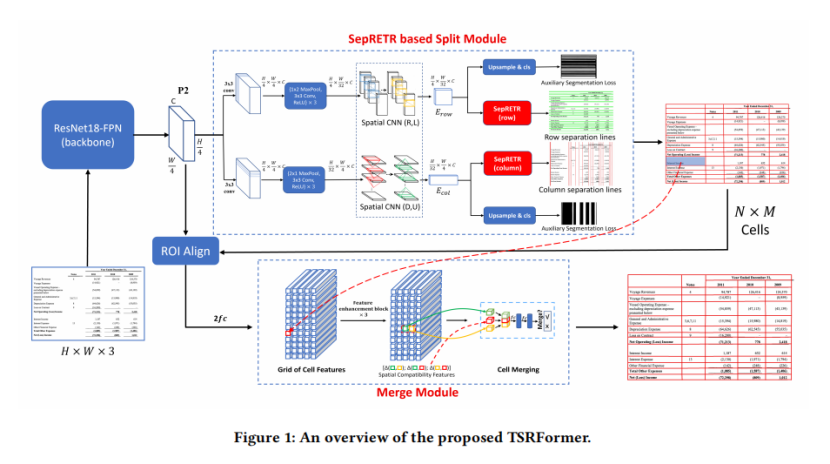
基于SepRETR的分割模块
在分割模块中,将两个并行分支附加到共享特征映射P 2上,分别预测行和列分隔符。每个分支由三个模块组成:(1)特征增强模块,生成上下文增强特征图;(2)基于SepRETR的分割线预测模块;(3)辅助分割线分割模块。
特征增强:如图1所示,作者添加一个3×3卷积层和3个重复下采样块,每个块由1×2最大池化层、3×3卷积层和ReLU激活函数组成,经过 P_2后依次生成下采样特征图 P_2 in R^{{frac H4} X{frac W {32}}XC}。然后,将两个级联空间CNN(SCNN)模块连接到 P_2^{}上,通过向整个特征图上向左右方向传播上下文信息,进一步增强其特征表示能力。以右方向为例,SCNN模块沿宽度方向将 P_2^{}分割成 frac W{32}
片,并从左向右依次传播信息。对于每个切片,它首先被发送到一个内核大小为9×1的卷积层,然后通过元素级的添加与下一个切片合并。在SCNN模块的帮助下,输出上下文增强的特征映射 E_{row}中的每个像素都可以利用来自两边的结构信息来获得更好的表示能力。
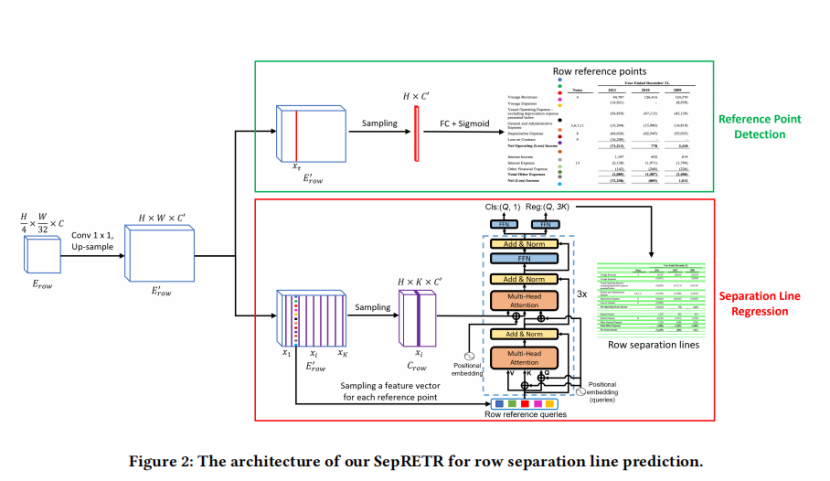
基于SepRETR的分离线预测:如图3所示,作者使用三条平行的曲线线分别表示每行分隔符的顶边界、中心线和底边界。每条曲线用K= 15个点表示,其x坐标分别设置为 x_1, x_2,…… x_k.对于每一行分隔符,其3K点的y坐标由作者的SepRETR模型直接预测。在这里,作者为第i个x的x坐标设置了 X_i=frac W{16}×{i}。对于列分支中的y坐标,作者只需要用H替换W。如图2所示,作者的SepRETR包含两个模块:一个参考点检测模块和一个用于分割线回归的DETR解码器。
参考点检测模块首先尝试从增强的特征映射
E_{row}
中预测每个行分隔符的参考点。将检测到的参考点的特征作为对象查询,并输入DETR解码器,为每个查询生成增强的嵌入。这些增强的查询嵌入然后通过前馈网络独立地解码为分离线坐标和类标签。这两个模块都连接到一个共享的高分辨率特征图上,该特征图是通过在
E_{row}^{}in R×W×C^{}中依次添加一个1×1的卷积层和一个上采样层而生成的。
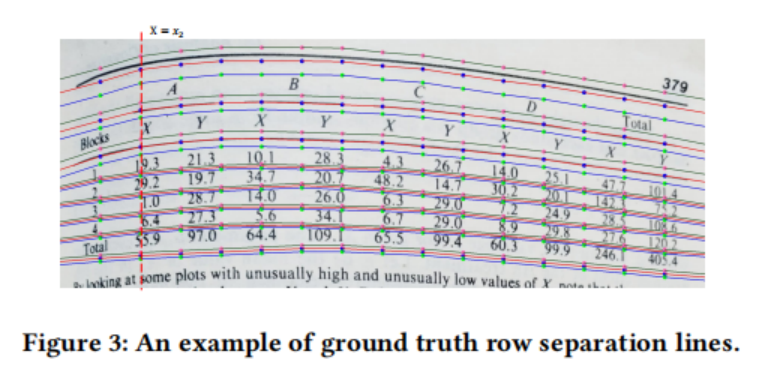
1) 参考点检测。该模块试图预测沿着原始图像的宽度方向的固定位置
X_r上的每个行分隔符的参考点。为此,
E_{row}^{}
的
X_r^{th}列中的每个像素被输入一个sigmoid分类器,以预测一个分数,以估计一个参考点位于其位置的概率(i,
x_r)。在这里,作者在所有实验中设置超参数
x_r
为
frac H4进行行线预测,
y_r为
frac H4进行列线预测。考虑到
E_{row}^{}
的
X_r^{th}列中每个像素的概率,作者通过在该列上使用7×1最大池化层来应用非最大抑制来删除重复的参考点。之后,选择前100个行参考点,并通过0.05的分数阈值进行进一步过滤。其余的行参考点作为行分割线回归模块中的DETR解码器的目标查询。
2) 分割线回归。为了提高效率,作者不使用transformer编码器来增强CNN主干网输出的特性。相反,作者将高分辨率特征图
E_{row}^{}
的
x_1^{th},
x_2^{th},...,
x_K^{th}列连接起来,以创建一个新的降采样特征图
C_{row}in R^{ H×K×C^{}}.然后,将
E_{row}^{}
从位置上提取的行参考点的特征视为对象查询,输入3层转换器解码器,与
C_{row}交互,进行分离线回归。位置的位置嵌入(x,y)是通过连接归一化坐标
frac xW和
frac yH的正弦嵌入来生成的,这与DETR中的相同。经transformer解码器增强后,将每个查询的特征分别馈入两个前馈网络中进行分类和回归。对于行分隔符回归的y坐标的GT被归一化为
frac {y_{gt}}H。
先验增强的二分图匹配:从输入图像中给定一组预测及其对应的GT对象,DETR使用Hungarian算法为系统预测分配GT标签。然而,作者发现DETR中原始的二分匹配算法在训练阶段是不稳定的,即在不同的训练时期可以对同一图像中的不同对象进行查询,这大大降低了模型的收敛速度。作者发现,在第一阶段检测到的大多数参考点在不同的训练阶段都位于对应行分隔符的顶部和底部边界之间,因此作者利用这些先验信息直接将每个参考点与最近的GT分隔符进行匹配。这样,匹配的结果在训练过程中就会变得稳定。具体来说,作者通过测量每个参考点和每个GT分隔符之间的距离来生成一个成本矩阵。如果一个参考点位于GT分隔符的顶部和底部边界之间,则成本被设置为从该参考点到该分隔符的GT参考点的距离。否则,成本将设置为INF。基于此成本矩阵,作者使用Hungarian算法在参考点和GT分割之间产生一个最优的二分匹配。在得到最优匹配结果后,作者进一步去掉了具有成本INF的对,以绕过不合理的标签分配。在后续的实验表明,通过作者的预先增强的二分匹配策略,作者的SepRETR的收敛速度变得更快。
辅助分割线分割:这个辅助分支旨在预测每个像素是否位于任何分隔符的区域内。作者在
E_{row}
之后添加了一个上采样操作,然后是一个1×1的卷积层和一个sigmoid分类器,来预测一个二进制掩模
M_{row}in R^{ W×H×1}来计算这种辅助损失。
基于关系网络的单元格合并
在分割线预测后,作者将行线与列线相交,生成一个单元格网格,并使用关系网络通过合并一些相邻的单元格来恢复生成单元格。如图1所示,作者首先使用RoI对齐算法从 P_2中根据每个单元的边界盒提取7×7×C特征图,然后输入每层512个节点的两层MLP,生成512d特征向量。这些单元特征可以排列在具有N行和M列的网格中,形成特征图 F_{cell}in R^{ N×M×512},然后通过三个重复的特征增强块来获得更广泛的上下文信息,并输入关系网络来预测相邻单元之间的关系。每个特征增强块包含三个并行分支,其中分别有一个行级最大池化层、一个列级最大池化层和一个3x3卷积层。这三个分支的输出特征映射被连接在一起,并通过一个1×1的卷积层进行卷积以进行降维。在关系网络中,对于每一对相邻的细胞,作者将它们的特征和18d空间相容性特征连接起来。然后在这个特征上应用一个二值分类器来预测这两个单元格是否应该合并。该分类器采用了一个2个隐藏层的MLP,每个隐藏层有512个节点和一个sigmoid激活函数。
损失函数
对于分割模块,作者以行分隔符预测为例,并将相应的损失项表示为 L_*^{row}。同样,作者也可以计算列分隔符预测的损失,记为 L_*^{col}。参考点检测:采用focal loss的一种变体来训练行参考点检测模块:
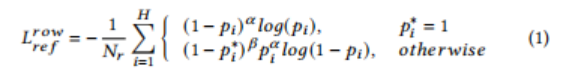
其中
N_r为行分割线数,α和β分别为设置为2和4的两个超参数,
P_i和
P_i^*为
E_{row}^{}
的
x_r^{th}列中
i^{th}像素的预测和GT标签。在这里,
P_i^*被非标准化高斯函数增强,它在分隔符的边界处被截断,以减少在GT参考点位置周围的惩罚。具体来说,让(
y_k,
x_r)表示
k^{th}行分隔符的GT参考点,它是该行分隔符的中心线与垂直线x=
X_r的交点。以k^{th}行分隔符顶部和底部边界的垂直距离作为其厚度,记为
w_k。那么,
P_i^*
可以定义如下:
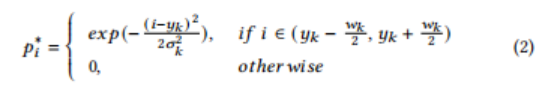
其中,
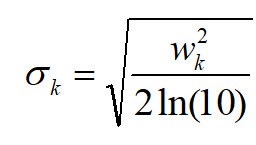
自适应于分隔器的厚度,以确保该行中的分隔符 P_i^*不小于0.1。
辅助分割损失:行分隔符的辅助分割损失是一个二进制交叉熵损失:
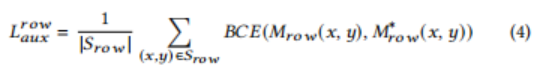
其中 S_{row}表示 M_{row}的采样像素集, M_{{row}^{(x,y)}}和 M_{{row}^{(x,y)}}^*分别表示 S_{row}像素(x,y)的预测和地面真实标签。仅当 M_{{row}^{(x,y)}}^*的像素位于行分隔符内时,它才为1,否则为0。

总损失:transformer中的所有模块都可以联合训练。整体损失函数如下:
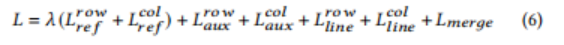
其中, lambda 是作者在实验中设置为0.2的控制参数。
实验:
数据集:
SciTSR包含12,000个训练样本和3,000个从科学文献中裁剪出来的轴对齐表的测试样本。作者还从测试集中选择了716个复杂的表,以创建一个更具挑战性的测试子集,称为SciTSRCOMP。在这个数据集中,单元格邻接关系度量被用作评价度量。
PubTabNet包含500,777个训练图像、9,115个验证图像和9,138张测试图像,它们是通过匹配科学文章的XML和PDF表示而生成的。所有的表格都是以轴向对齐的。由于没有发布测试集的注释,所以作者只报告验证集上的结果。论文提出了一种新的基于树编辑距离的相似度(TEDS)度量,该度量既可以识别表结构识别,也可以识别表结构识别OCR错误。然而,由于不同的TSR方法使用不同的OCR模型不同,考虑OCR误差可能会导致不公平的比较。最近的一些工作提出了一种改进的TEDS度量TEDS-Struct,仅通过忽略OCR误差来评估表结构识别精度。作者还使用这个修改后的度量值来评估作者在这个数据集上的方法。
WTW包含了从自然复杂场景中收集到的10,970张训练图像和3,611张测试图像。该数据集只关注有边界的表格对象,并包含表id、表格单元格坐标和行/列信息的注释信息。作者从原始图像中裁剪表区域用于训练和测试,并使用单元邻接关系(IoU=0.6)作为该数据集的评估指标。
In-House数据集包含40,590张训练图像和1,053张测试图像,这些图像是从异构文档图像中裁剪出来的,包括科学出版物、财务报表、发票等。这个数据集中的大多数图像都是由相机捕获的,所以这些图像中的表格可能是倾斜的,甚至是弯曲的。一些例子见图4和图5。cTDaR TrackB度量用于评估。作者使用GT文本框作为表格内容,并基于IoU=0.9报告结果。
实验结果:
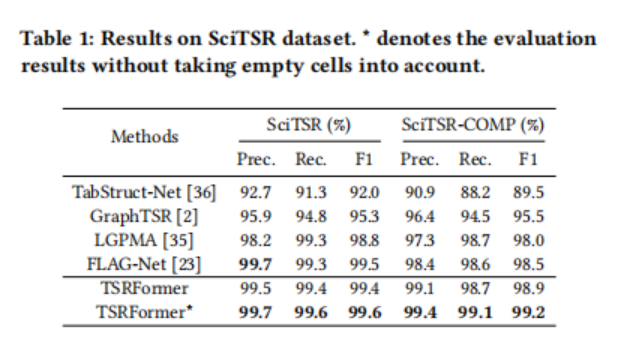
作者在公共数据集SciTSR、PubTabNet和WTW上将提出的TSRFormer与几种最先进的方法进行了比较。对于SciTSR,由于其他方法提供的评估工具包含两种不同的设置(考虑或忽略空单元格),并且以前的一些工作没有解释他们使用了哪一种设置,所以实验报告了这两种设置的结果。如表1所示,论文的方法分别在测试集和复杂的子集上取得了最先进的性能。在SciTSR-COMP上的良好结果表明,论文的方法对复杂的表具有更强的鲁棒性。
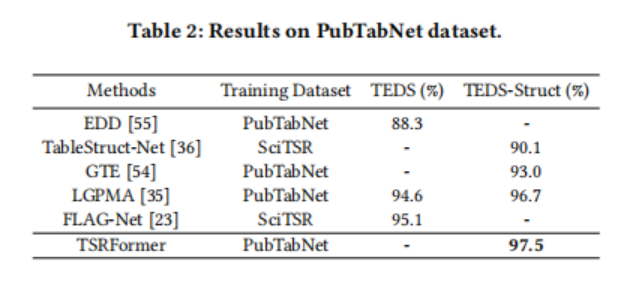
在PubTabNet上,如表2所示,论文的方法在TEDS-Struct评分上达到了97.5%,比LGPMA(ICDAR 2021科学文献解析任务B竞赛中的获胜者)高0.8%。
 为了验证论文的方法在自然场景中边界扭曲/弯曲表格对象的有效性,作者在WTW数据集上进行了实验,表3的结果表明,论文的方法在f1-score上比cycle-centernet(专门为此场景设计)好1.0%
为了验证论文的方法在自然场景中边界扭曲/弯曲表格对象的有效性,作者在WTW数据集上进行了实验,表3的结果表明,论文的方法在f1-score上比cycle-centernet(专门为此场景设计)好1.0%
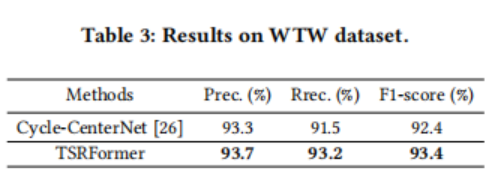
为了验证TSRFrormer对更具有挑战性的无边界表的有效性,作者重新实现了另一种基于分割和合并的方法SPLERGE,并在几个数据集上与论文的方法进行了比较。为了公平比较,作者利用TSRFromer相同的模型架构,只实现了另一个分割线预测模块,该模块首先通过行/列级池增强特征映射,然后通过对水平/垂直切片中的像素进行分类来预测轴对齐的分隔符。如表4所示,重新实现的SPLERGE可以在SciTSR和PubTabNet数据集上取得竞争性的结果,而在具有挑战性的内部数据集上,它仍然比TSRFromer低11.4%。
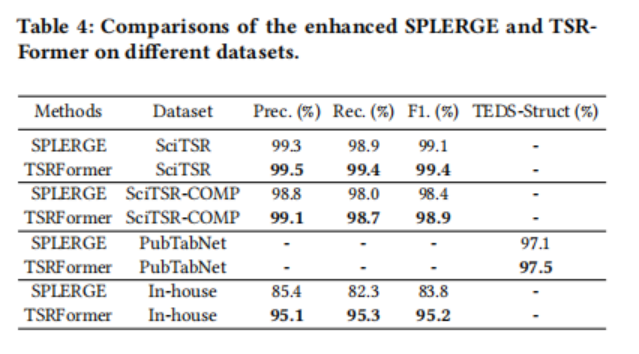
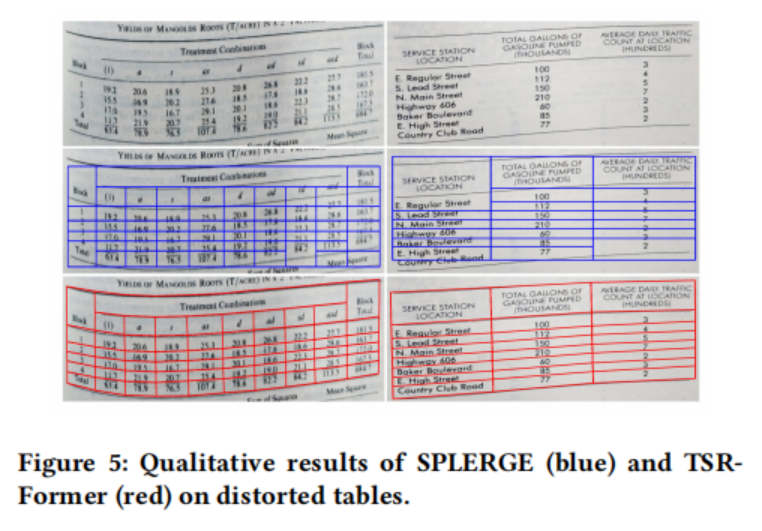
图5和图4中的定性结果表明,论文的方法对于具有复杂结构、无边界单元格、大空白空间、空白或跨行单元格以及扭曲甚至弯曲形状的表格具有鲁棒性。

消融实验:
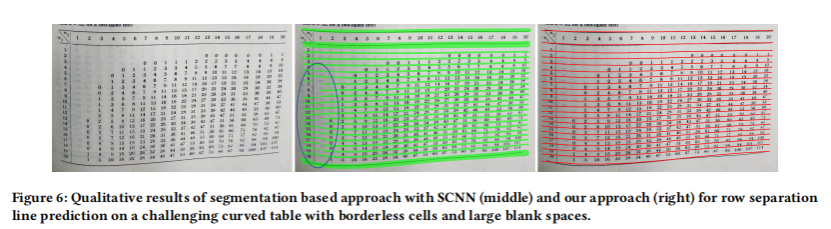
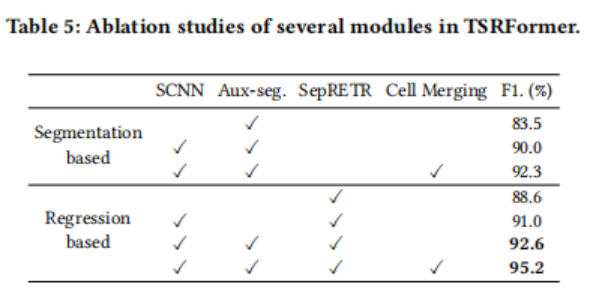
基于SepRETR的分割模块的有效性:为了验证基于回归的分离预测模块的有效性,作者采用RobusTabNet,去掉基于分割线回归模块SepRETR,直接使用辅助分离分割分支进行分离线预测,实现了另一个基于分割的分割模块。启发式mask-to-line模块也与RobusTabNet中的相同。表5中的结果表明,论文的分离回归模块明显优于基于分割的分割模块。图6显示了一些定性的结果。后处理模块很难很好地处理这种低质量的mask。相比之下,基于回归的方法是启发式的,对这些具有挑战性的表鲁棒。
SepRETR设计的消融研究:论文还进行了以下消融研究,以进一步研究SepRETR中三个关键成分的贡献,即transformer解码器,用于cross-attention和集合预测的特征。对于没有集预测的实验,实验设计了一个启发式的标签分配规则。如果一个参考点位于分隔符的两个边界之间,则其对应
| 联系人: | 透明七彩巨人 |
|---|---|
| Email: | weok168@gmail.com |
